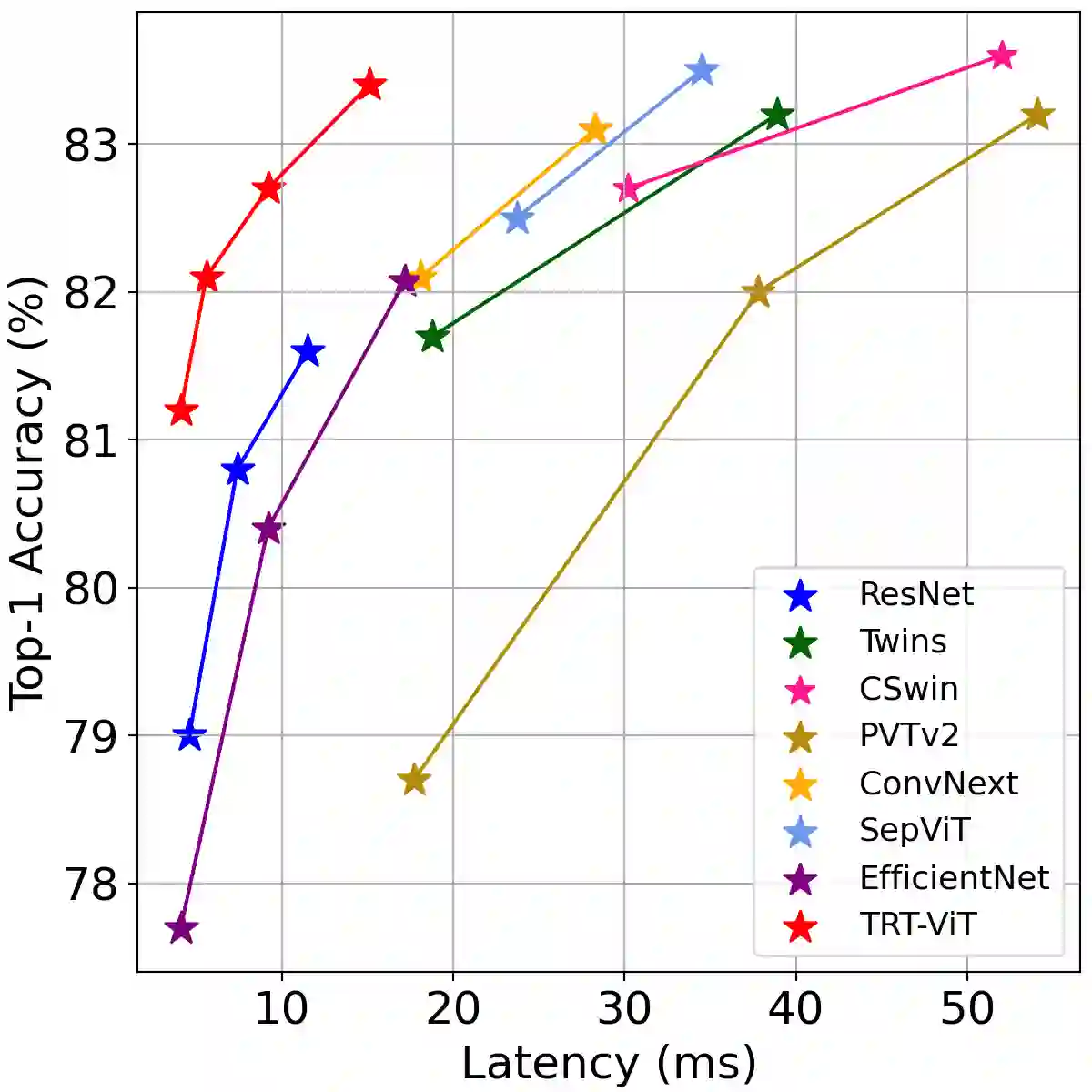
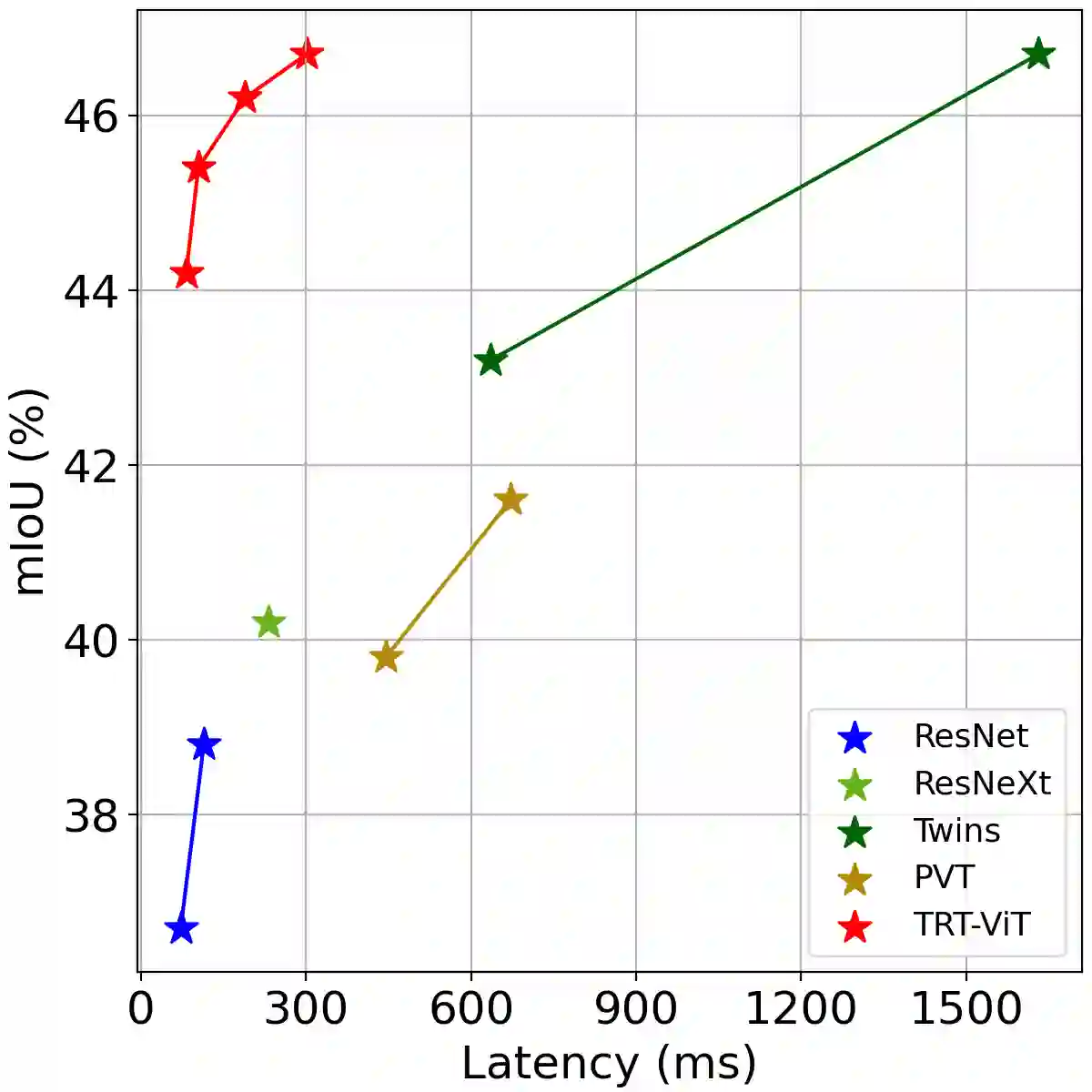
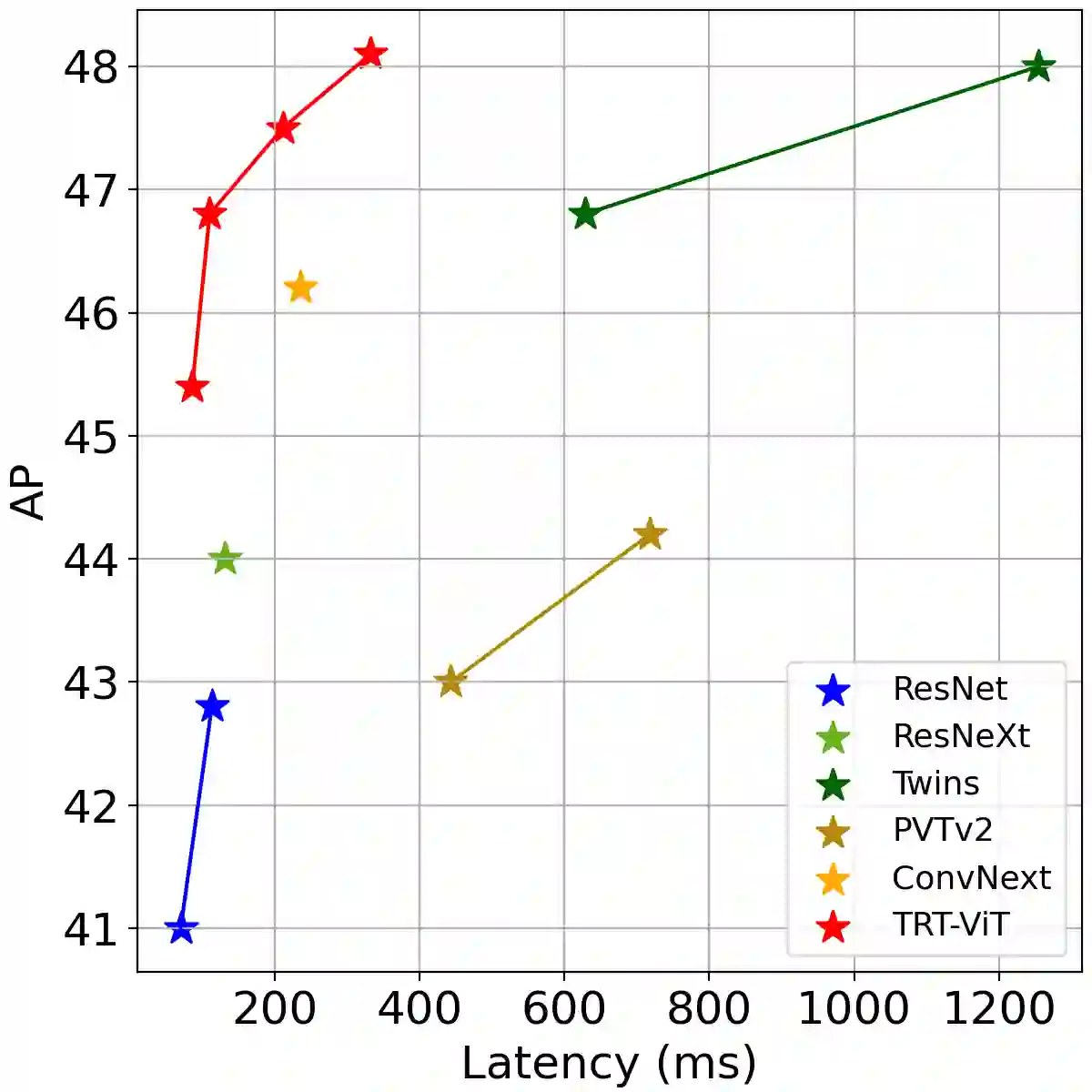
We revisit the existing excellent Transformers from the perspective of practical application. Most of them are not even as efficient as the basic ResNets series and deviate from the realistic deployment scenario. It may be due to the current criterion to measure computation efficiency, such as FLOPs or parameters is one-sided, sub-optimal, and hardware-insensitive. Thus, this paper directly treats the TensorRT latency on the specific hardware as an efficiency metric, which provides more comprehensive feedback involving computational capacity, memory cost, and bandwidth. Based on a series of controlled experiments, this work derives four practical guidelines for TensorRT-oriented and deployment-friendly network design, e.g., early CNN and late Transformer at stage-level, early Transformer and late CNN at block-level. Accordingly, a family of TensortRT-oriented Transformers is presented, abbreviated as TRT-ViT. Extensive experiments demonstrate that TRT-ViT significantly outperforms existing ConvNets and vision Transformers with respect to the latency/accuracy trade-off across diverse visual tasks, e.g., image classification, object detection and semantic segmentation. For example, at 82.7% ImageNet-1k top-1 accuracy, TRT-ViT is 2.7$\times$ faster than CSWin and 2.0$\times$ faster than Twins. On the MS-COCO object detection task, TRT-ViT achieves comparable performance with Twins, while the inference speed is increased by 2.8$\times$.
翻译:我们从实际应用的角度重新审视现有的极佳变异器。 大部分变异器甚至不如基本的 ResNet 序列那么高效, 并且偏离了现实的部署设想。 这可能是由于目前测量计算效率的标准, 如 FLOP 或参数是片面的、 亚最佳的和硬件不敏感的。 因此, 本文直接将特定硬件的TensorRT 宽度视为一种效率衡量标准, 它提供了更全面的反馈, 包括计算能力、 记忆成本和带宽。 根据一系列受控实验, 这项工作为TensorRT 和部署友好的物体网络设计提供了四个实用指南。 例如, 早期CNN 和晚变异器在阶段一级、 早期变异器和晚的CNN 。 因此, 以TensortRT 为导向的变异器组合被缩写为TRT- ViT 。 广泛的实验表明, TRT- ViT 大大超出了现有的CVEMNet 和愿景变异器, 与Lative/ centreal Trade- transal- cal- trafferationalations delations delations and lexal- lexal- legal- lex- leg- leg- laves- lex- lax- leg- lax- leg- leg- lax- lex- leg- leg- lax- lax- lex- lex- e- lex- slations- leg- leg- leg- leg- lax