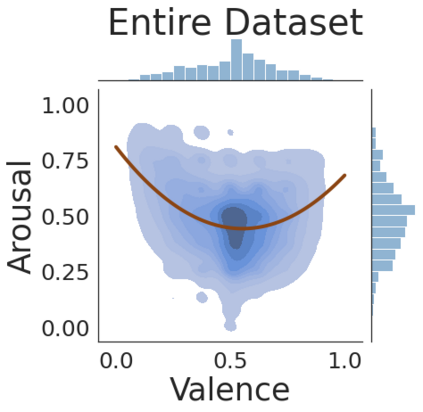
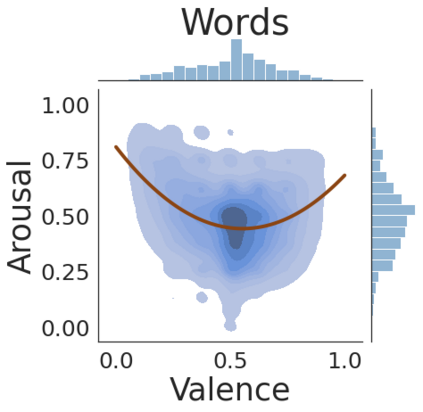
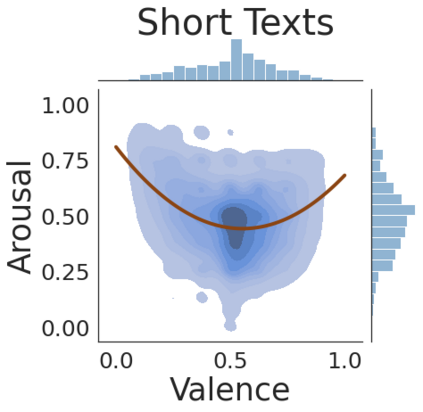
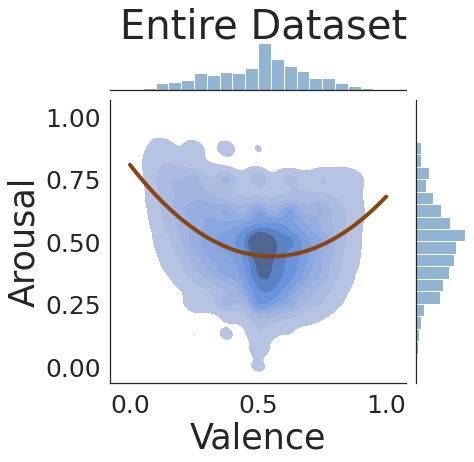
The analysis of emotions expressed in text has numerous applications. In contrast to categorical analysis, focused on classifying emotions according to a pre-defined set of common classes, dimensional approaches can offer a more nuanced way to distinguish between different emotions. Still, dimensional methods have been less studied in the literature. Considering a valence-arousal dimensional space, this work assesses the use of pre-trained Transformers to predict these two dimensions on a continuous scale, with input texts from multiple languages and domains. We specifically combined multiple annotated datasets from previous studies, corresponding to either emotional lexica or short text documents, and evaluated models of multiple sizes and trained under different settings. Our results show that model size can have a significant impact on the quality of predictions, and that by fine-tuning a large model we can confidently predict valence and arousal in multiple languages. We make available the code, models, and supporting data.
翻译:文本中表达的情感分析有许多应用。与绝对分析不同,重点是根据一套预先定义的共同类别对情感进行分类,而维维方法则可以提供一种更细微的区分不同情感的方法。然而,在文献中,对维维方法的研究较少。考虑到一个价值-振奋的维维空间,这项工作评估了预先训练的变异器在连续规模上对这两个维度进行预测的使用情况,包括来自多种语言和领域的输入文本。我们特别结合了以前研究中多套附加说明的数据集,这些数据集与情感法则或短文本文件相对应,并评价了多种尺寸的模型,并在不同的环境下进行了培训。我们的结果显示,模型的规模可以对预测质量产生重大影响,而通过微调一个大的模型,我们可以有信心地预测多种语言的价值和振奋度。我们提供了代码、模型和辅助数据。</s>