
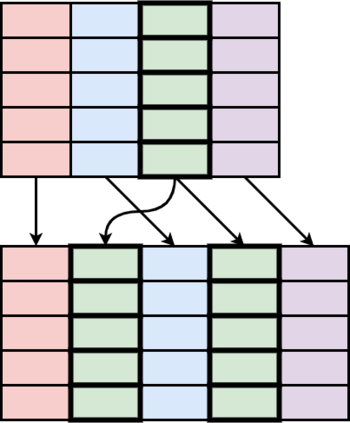
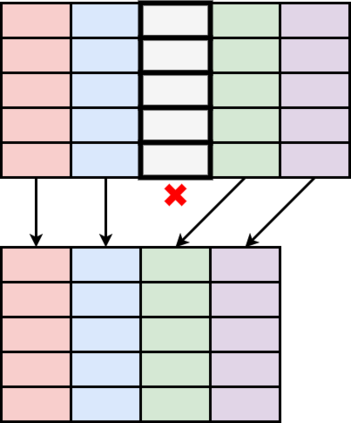
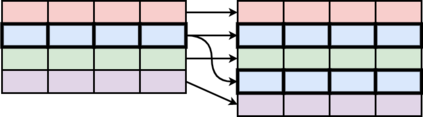
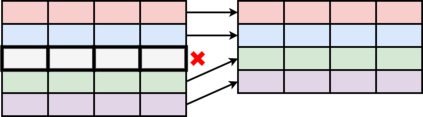
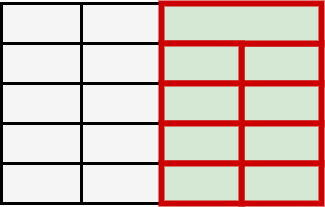
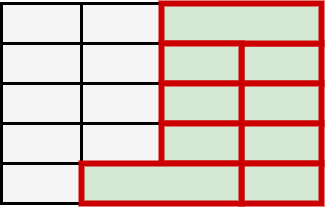
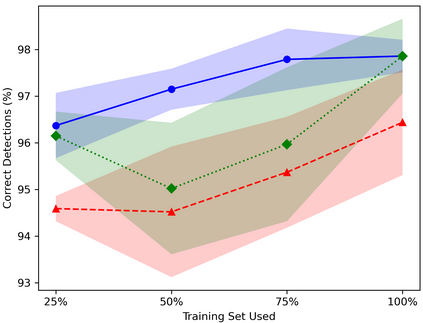
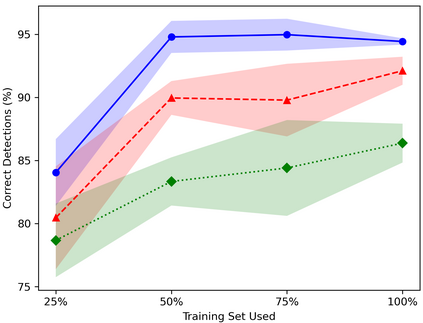
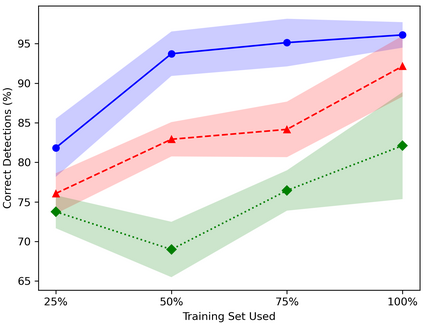
Table Structure Recognition is an essential part of end-to-end tabular data extraction in document images. The recent success of deep learning model architectures in computer vision remains to be non-reflective in table structure recognition, largely because extensive datasets for this domain are still unavailable while labeling new data is expensive and time-consuming. Traditionally, in computer vision, these challenges are addressed by standard augmentation techniques that are based on image transformations like color jittering and random cropping. As demonstrated by our experiments, these techniques are not effective for the task of table structure recognition. In this paper, we propose TabAug, a re-imagined Data Augmentation technique that produces structural changes in table images through replication and deletion of rows and columns. It also consists of a data-driven probabilistic model that allows control over the augmentation process. To demonstrate the efficacy of our approach, we perform experimentation on ICDAR 2013 dataset where our approach shows consistent improvements in all aspects of the evaluation metrics, with cell-level correct detections improving from 92.16% to 96.11% over the baseline.
翻译:表格结构识别是文档图像中端到端表数据提取的一个必要部分。 计算机视觉中深学习模型结构最近的成功在表格结构识别中仍然是非反光性的, 主要是因为这个领域仍然缺乏广泛的数据集, 而新数据标签又昂贵且耗时。 在计算机的视觉中, 这些挑战传统上是通过基于图像转换的标准增强技术来解决的, 其基础是彩色喷射和随机裁剪等图像转换。 正如我们的实验所证明的, 这些技术对表格结构识别任务并不有效。 在本文中, 我们提议采用TabAug, 一种重新想象的数据增强技术, 通过复制和删除行和列,在表格图像中产生结构性变化。 它还包括一种数据驱动的概率性模型, 从而能够控制增强过程。 为了展示我们的方法的有效性, 我们在ICDAR 2013 数据集上进行了实验, 在那里我们的方法显示评估指标的各个方面都得到了一致的改进, 细胞级正确检测率从92. 16%提高到96.11% 超过基线。








相关内容

- Today (iOS and OS X): widgets for the Today view of Notification Center
- Share (iOS and OS X): post content to web services or share content with others
- Actions (iOS and OS X): app extensions to view or manipulate inside another app
- Photo Editing (iOS): edit a photo or video in Apple's Photos app with extensions from a third-party apps
- Finder Sync (OS X): remote file storage in the Finder with support for Finder content annotation
- Storage Provider (iOS): an interface between files inside an app and other apps on a user's device
- Custom Keyboard (iOS): system-wide alternative keyboards
Source: iOS 8 Extensions: Apple’s Plan for a Powerful App Ecosystem

