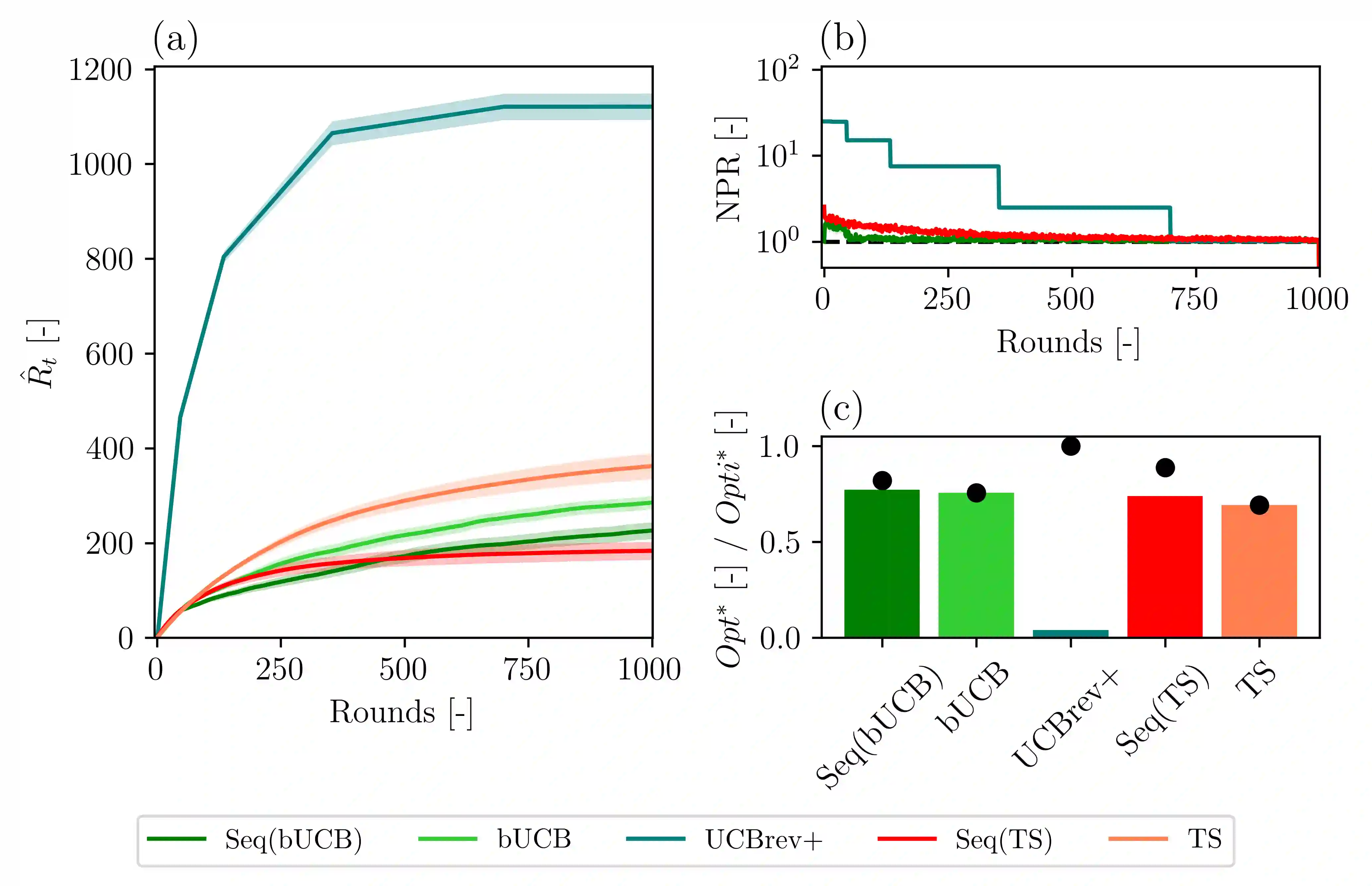
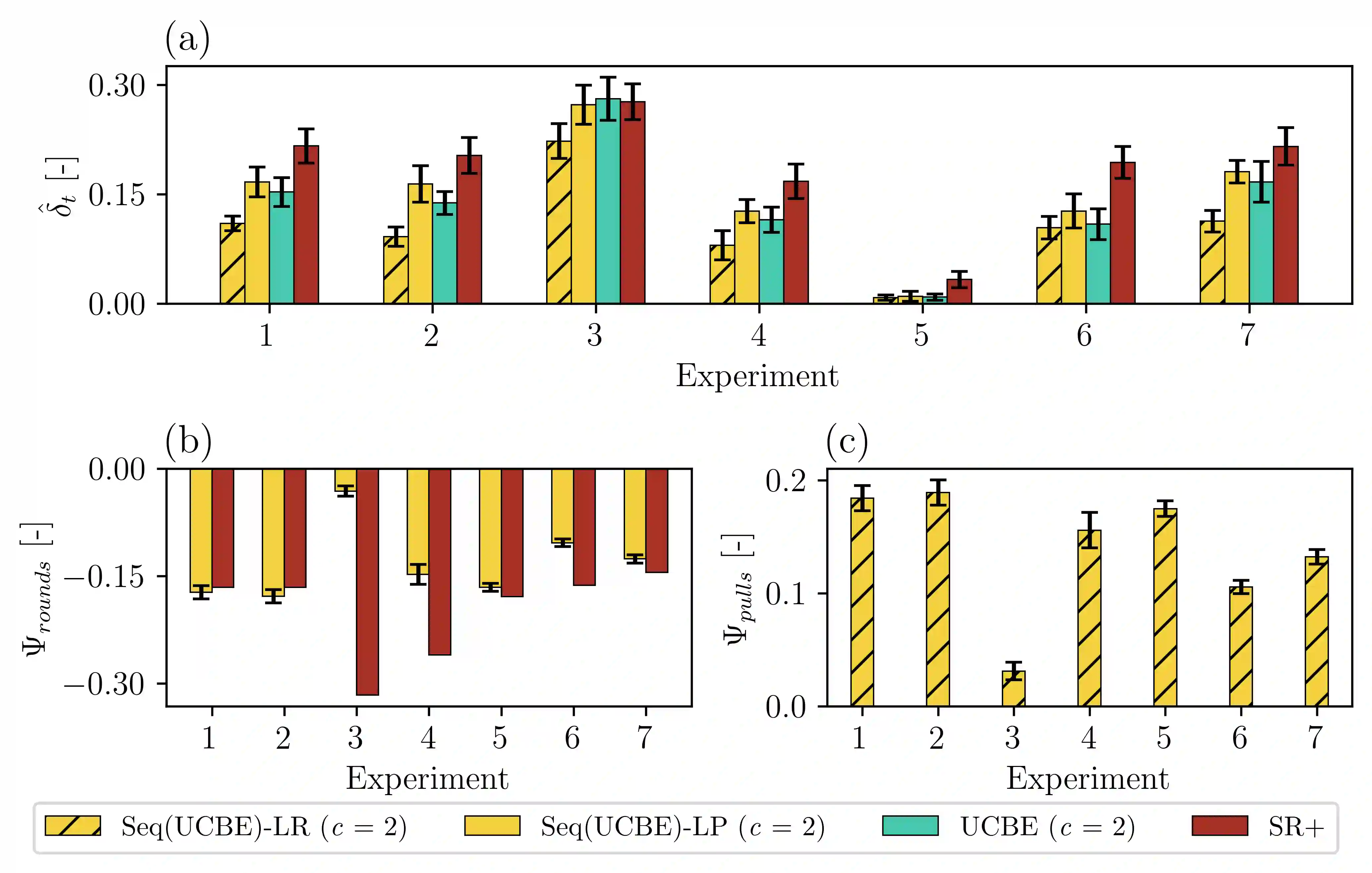
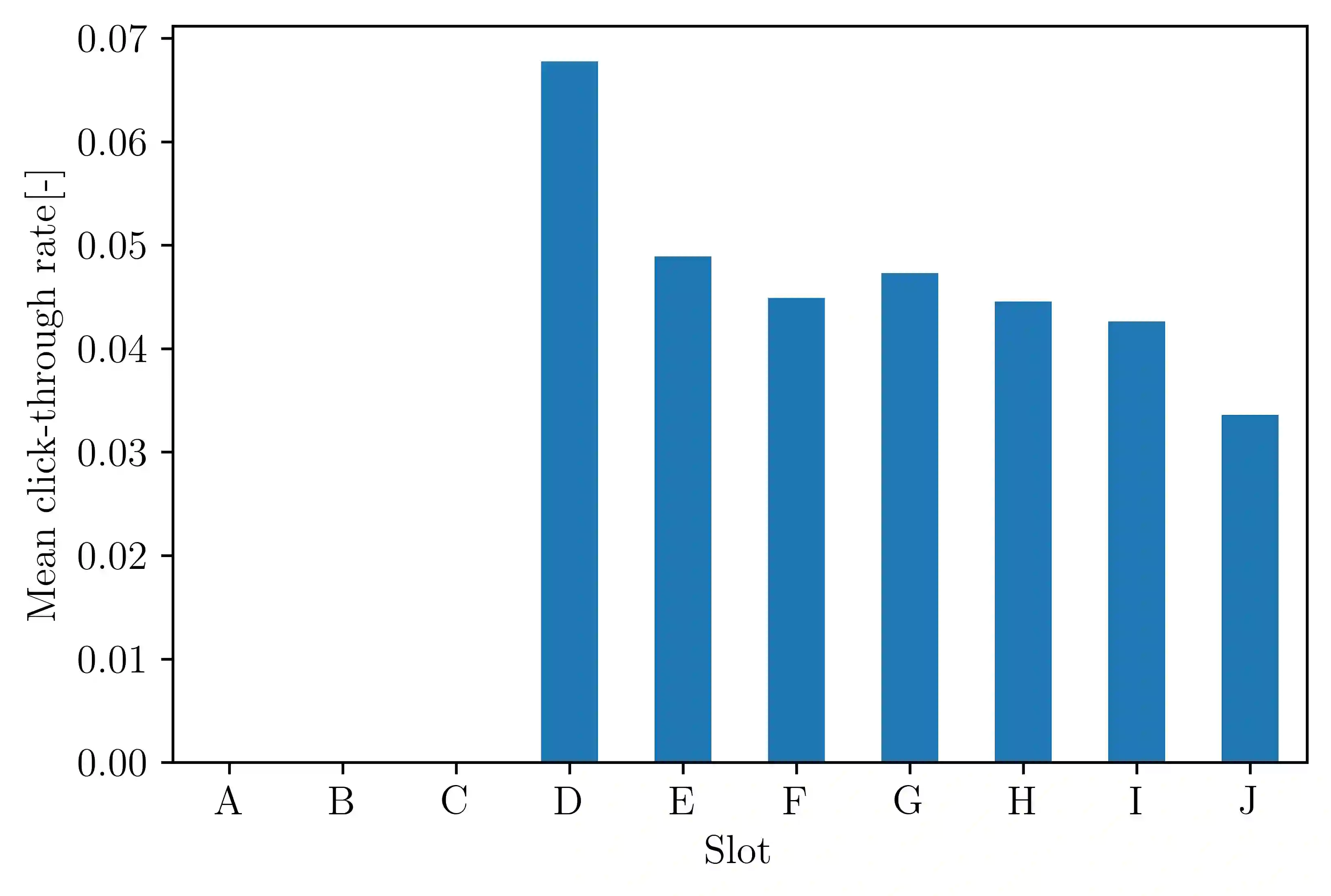
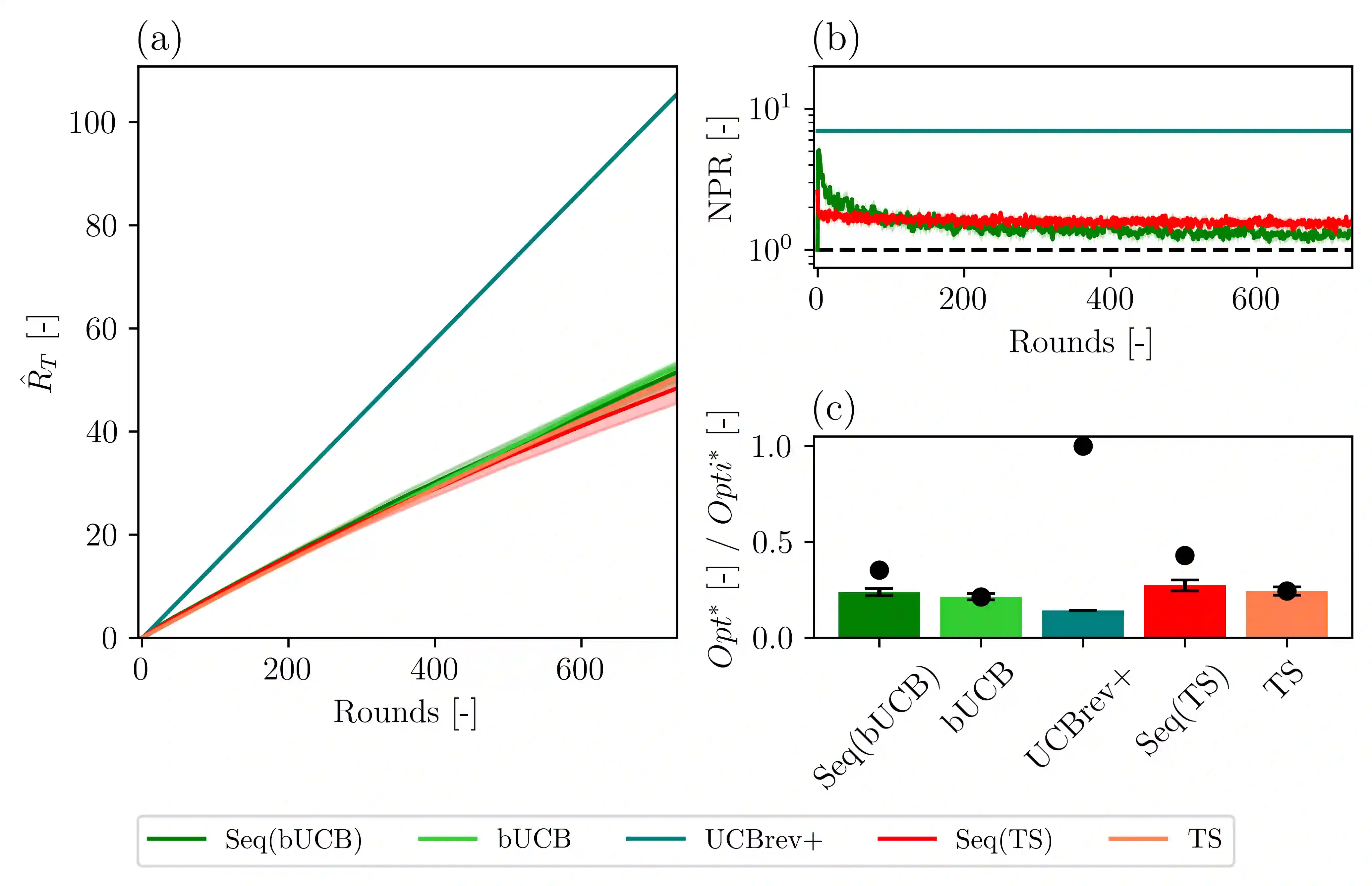
Although the classical version of the Multi-Armed Bandits (MAB) framework has been applied successfully to several practical problems, in many real-world applications, the possible actions are not presented to the learner simultaneously, such as in the Internet campaign management and environmental monitoring settings. Instead, in such applications, a set of options is presented sequentially to the learner within a time span, and this process is repeated throughout a time horizon. At each time, the learner is asked whether to select the proposed option or not. We define this scenario as the Sequential Pull/No-pull Bandit setting, and we propose a meta-algorithm, namely Sequential Pull/No-pull for MAB (Seq), to adapt any classical MAB policy to better suit this setting for both the regret minimization and best-arm identification problems. By allowing the selection of multiple arms within a round, the proposed meta-algorithm gathers more information, especially in the first rounds, characterized by a high uncertainty in the arms estimate value. At the same time, the adapted algorithms provide the same theoretical guarantees as the classical policy employed. The Seq meta-algorithm was extensively tested and compared with classical MAB policies on synthetic and real-world datasets from advertising and environmental monitoring applications, highlighting its good empirical performances.
翻译:虽然经典的多武装强盗框架(MAB)已经成功地应用于若干实际问题,但在许多现实世界应用中,可能的行动并没有同时向学习者提出,例如在互联网运动管理和环境监测环境中。相反,在这种应用中,在一段时间内,向学习者按顺序向学习者提出一套选择方案,整个时间跨度重复这一进程。每次,都询问学习者是否选择拟议的选择方案。我们将这一设想界定为顺序拉/不拉-不拉-强盗设置,我们提议一个元和数,即顺序拉/不拉(Seq),以调整任何经典的MAB政策,使之更好地适应这种环境环境环境环境环境环境环境环境,同时广泛测试了传统政策。