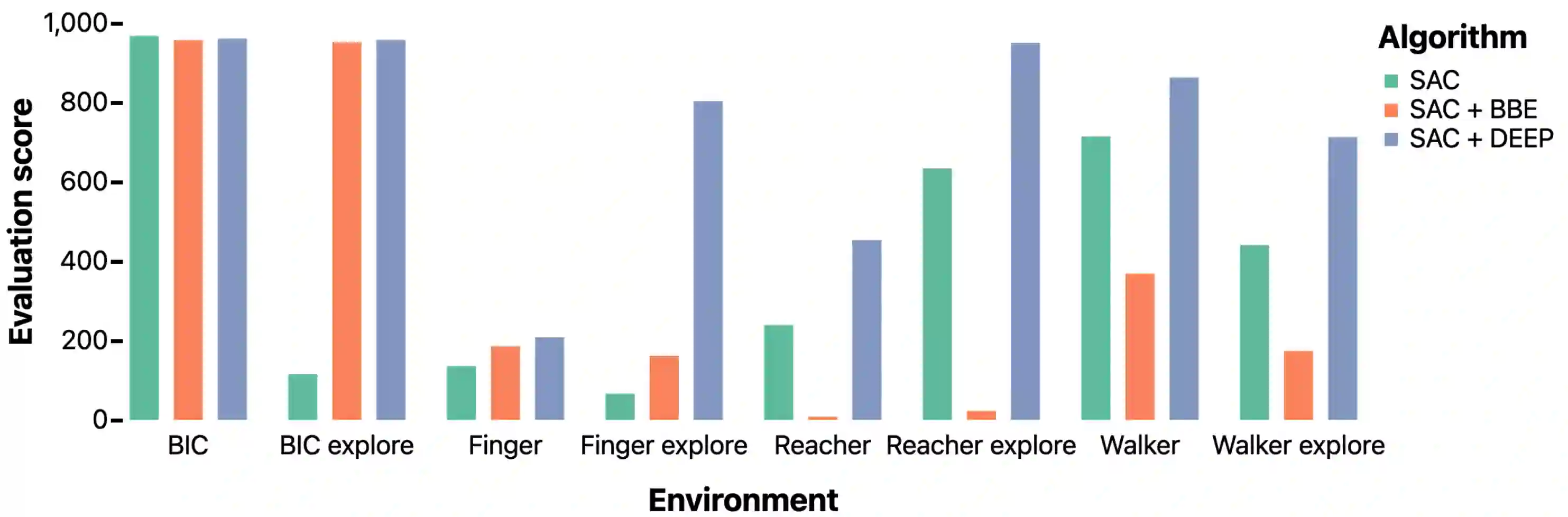
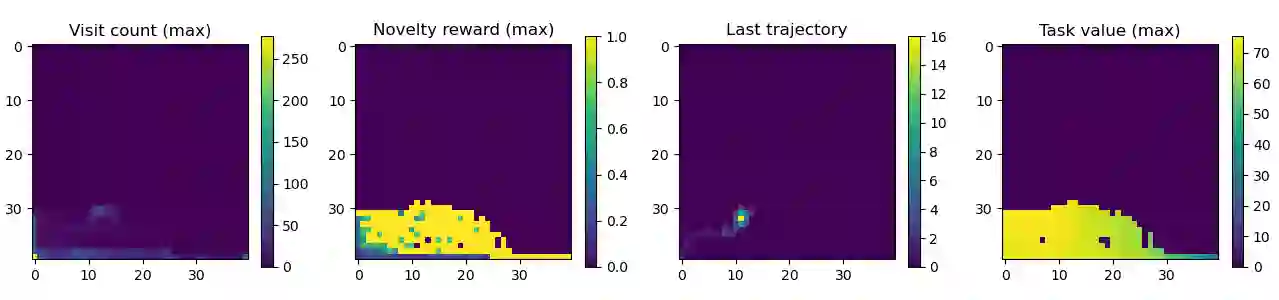
Despite the close connection between exploration and sample efficiency, most state of the art reinforcement learning algorithms include no considerations for exploration beyond maximizing the entropy of the policy. In this work we address this seeming missed opportunity. We observe that the most common formulation of directed exploration in deep RL, known as bonus-based exploration (BBE), suffers from bias and slow coverage in the few-sample regime. This causes BBE to be actively detrimental to policy learning in many control tasks. We show that by decoupling the task policy from the exploration policy, directed exploration can be highly effective for sample-efficient continuous control. Our method, Decoupled Exploration and Exploitation Policies (DEEP), can be combined with any off-policy RL algorithm without modification. When used in conjunction with soft actor-critic, DEEP incurs no performance penalty in densely-rewarding environments. On sparse environments, DEEP gives a several-fold improvement in data efficiency due to better exploration.
翻译:尽管勘探与采样效率之间有着密切的联系,但大多数先进的强化学习算法都不考虑勘探问题,而只是尽量扩大政策昆虫。在这项工作中,我们讨论了这一似乎错失的机会。我们发现,在深RL(称为以奖金为基础的勘探(BBE))中,最常用的定向勘探方式在少数抽样制度下是偏向性的,覆盖面缓慢。这导致BBE在许多控制任务中积极损害政策学习。我们表明,通过将任务政策与勘探政策脱钩,定向勘探对于采样效率高的持续控制可能非常有效。我们的方法、分解的勘探和开发政策(DEEP)可以与任何非政策RL算法不作任何修改地结合起来。当与软的行为者-批评一起使用时,DEEP在密集的环境中不会受到性能处罚。在稀少的环境中,DEEP通过更好的勘探,使数据效率得到几倍的提高。