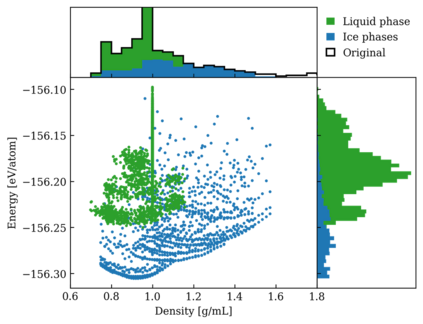
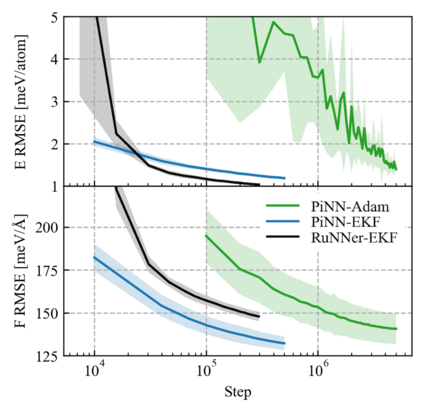
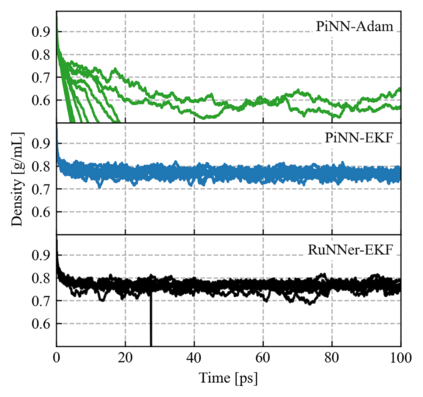
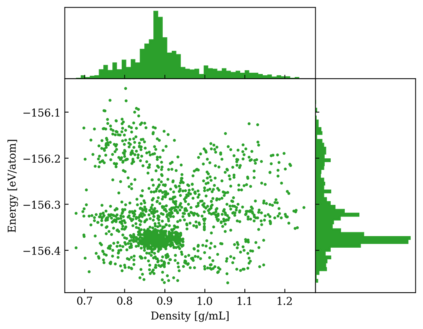
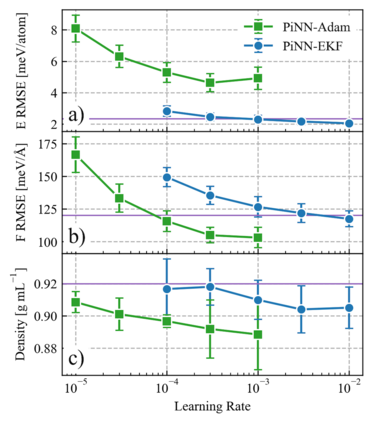
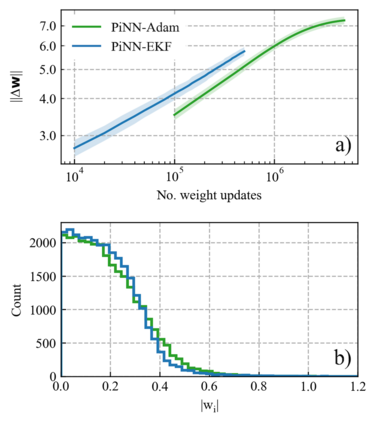
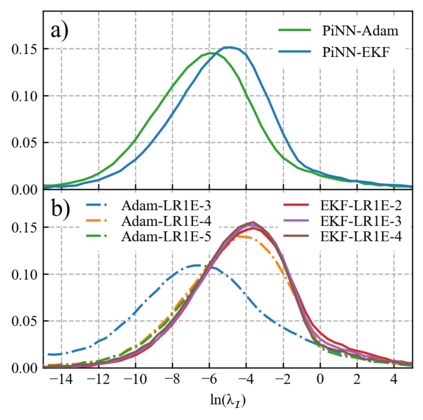
One hidden yet important issue for developing neural network potentials (NNPs) is the choice of training algorithm. Here we compare the performance of two popular training algorithms, the adaptive moment estimation algorithm (Adam) and the extended Kalman filter algorithm (EKF), using the Behler-Parrinello neural network (BPNN) and two publicly accessible datasets of liquid water. It is found that NNPs trained with EKF are more transferable and less sensitive to the value of the learning rate, as compared to Adam. In both cases, error metrics of the test set do not always serve as a good indicator for the actual performance of NNPs. Instead, we show that their performance correlates well with a Fisher information based similarity measure.
翻译:开发神经网络潜力(NNPs)的一个隐藏但重要的问题是培训算法的选择。 我们在这里比较两种通用培训算法的性能,即适应性瞬间估计算法(Adam)和延长的卡尔曼过滤算法(EKF),使用Behler-Parrinello神经网络(BPNN)和两个可公开查阅的液体水数据集,发现与Adam相比,接受过EKF培训的NNPs更具有可转移性,对学习率值的敏感度更低。 在这两种情况下,测试组的误差指标并不总是作为NNPs实际性能的良好指标。 相反,我们表明其性能与基于渔业信息的类似性衡量标准密切相关。