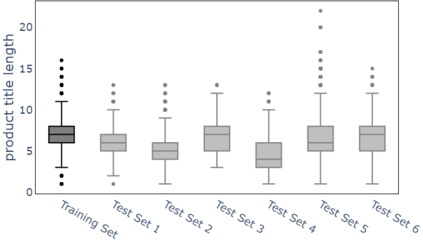
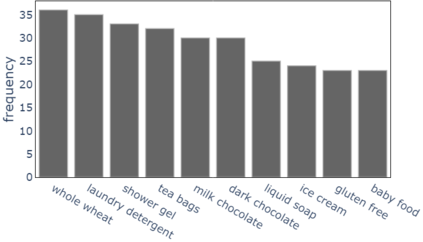
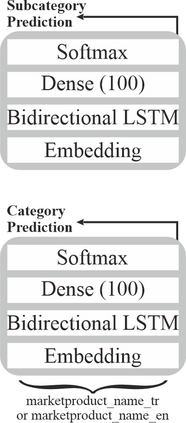
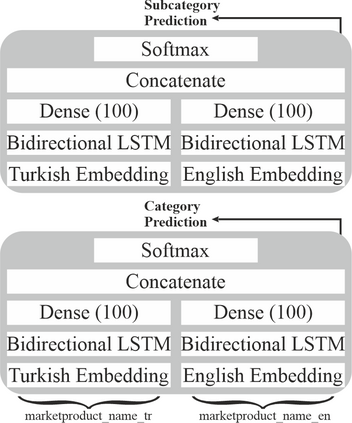
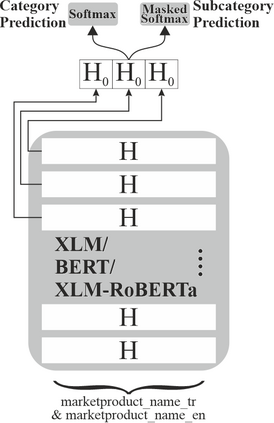
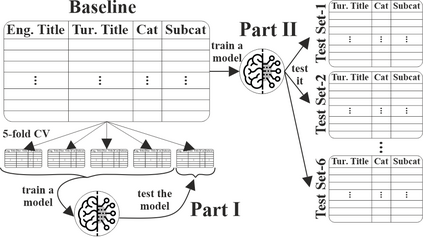
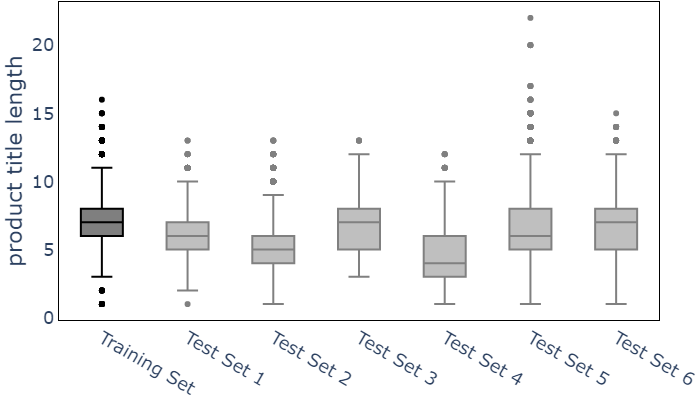
In an online shopping platform, a detailed classification of the products facilitates user navigation. It also helps online retailers keep track of the price fluctuations in a certain industry or special discounts on a specific product category. Moreover, an automated classification system may help to pinpoint incorrect or subjective categories suggested by an operator. In this study, we focus on product title classification of the grocery products. We perform a comprehensive comparison of six different text classification models to establish a strong baseline for this task, which involves testing both traditional and recent machine learning methods. In our experiments, we investigate the generalizability of the trained models to the products of other online retailers, the dynamic masking of infeasible subcategories for pretrained language models, and the benefits of incorporating product titles in multiple languages. Our numerical results indicate that dynamic masking of subcategories is effective in improving prediction accuracy. In addition, we observe that using bilingual product titles is generally beneficial, and neural network-based models perform significantly better than SVM and XGBoost models. Lastly, we investigate the reasons for the misclassified products and propose future research directions to further enhance the prediction models.
翻译:在网上购物平台上,产品的详细分类有助于用户导航,还有助于在线零售商跟踪特定行业的价格波动或特定产品类别的特殊折扣;此外,自动化分类系统可能有助于确定运营商建议的不正确或主观类别;在本研究中,我们侧重于杂货产品的产品标题分类;我们对六种不同的文本分类模型进行全面比较,以便为这项任务建立强有力的基准,其中包括测试传统和最近的机器学习方法;在实验中,我们调查经过培训的模型与其他在线零售商产品的一般可操作性、预先培训的语言模型不可行的子分类动态遮掩以及将产品标题纳入多种语言的好处。我们的数字结果显示,动态的子分类掩码对于提高预测准确性是有效的。此外,我们注意到,使用双语产品名称总体上是有益的,而以神经网络为基础的模型比SVM和XGBoost模型效果要好得多。最后,我们调查了错误分类产品的原因,并提出未来研究方向,以进一步加强预测模型。