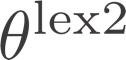Retrieval models based on dense representations in semantic space have become an indispensable branch for first-stage retrieval. These retrievers benefit from surging advances in representation learning towards compressive global sequence-level embeddings. However, they are prone to overlook local salient phrases and entity mentions in texts, which usually play pivot roles in first-stage retrieval. To mitigate this weakness, we propose to make a dense retriever align a well-performing lexicon-aware representation model. The alignment is achieved by weakened knowledge distillations to enlighten the retriever via two aspects -- 1) a lexicon-augmented contrastive objective to challenge the dense encoder and 2) a pair-wise rank-consistent regularization to make dense model's behavior incline to the other. We evaluate our model on three public benchmarks, which shows that with a comparable lexicon-aware retriever as the teacher, our proposed dense one can bring consistent and significant improvements, and even outdo its teacher. In addition, we found our improvement on the dense retriever is complementary to the standard ranker distillation, which can further lift state-of-the-art performance.
翻译:以语义空间密度代表制为基础的检索模型已成为第一阶段检索的一个不可或缺的分支。这些检索者受益于在代表性学习方面取得的飞速进步,以形成压缩的全球序列层嵌入器。然而,它们容易忽略文本中提及的本地显著短语和实体,这些短语和实体通常在第一阶段检索中起着枢纽作用。为了减轻这一弱点,我们建议使一个密集的检索者调整一个良好的词汇-觉悟代表制模式。通过削弱知识蒸馏,通过两个方面来启发检索者,实现了这种一致性:(1) 一种强化的词汇对比性目标,以挑战密集的编码器;和(2) 双对称的一等一致的正规化,以使密集模型的行为与另一类相连接。我们根据三个公共基准评估我们的模型,这表明,与教师相似的词汇-觉醒检索器相比,我们提议的密度的检索器可以带来一致和显著的改进,甚至超越了教师。此外,我们发现,在密集的检索者上所作的改进是对标准级蒸馏器的补充,可以进一步提升状态的性能。