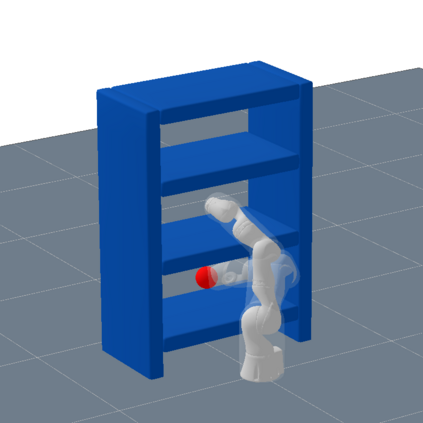
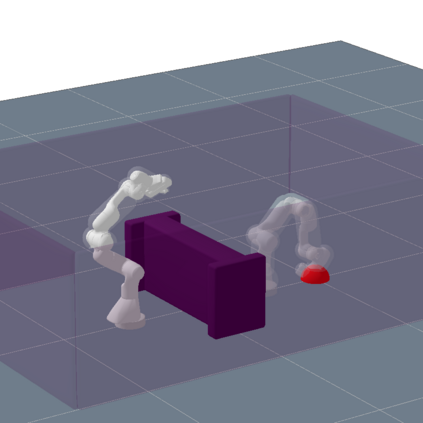
Optimal sampling based motion planning and trajectory optimization are two competing frameworks to generate optimal motion plans. Both frameworks have complementary properties: Sampling based planners are typically slow to converge, but provide optimality guarantees. Trajectory optimizers, however, are typically fast to converge, but do not provide global optimality guarantees in nonconvex problems, e.g. scenarios with obstacles. To achieve the best of both worlds, we introduce a new planner, BITKOMO, which integrates the asymptotically optimal Batch Informed Trees (BIT*) planner with the K-Order Markov Optimization (KOMO) trajectory optimization framework. Our planner is anytime and maintains the same asymptotic optimality guarantees provided by BIT*, while also exploiting the fast convergence of the KOMO trajectory optimizer. We experimentally evaluate our planner on manipulation scenarios that involve high dimensional configuration spaces, with up to two 7-DoF manipulators, obstacles and narrow passages. BITKOMO performs better than KOMO by succeeding even when KOMO fails, and it outperforms BIT* in terms of convergence to the optimal solution.
翻译:最佳抽样的动作规划和轨迹优化是产生最佳运动计划的两个相互竞争的框架。两个框架都具有互补的特性:以抽样为基础的规划者通常会缓慢地汇合,但提供最佳性保证。不过,轨迹优化者通常会很快汇合,但不会在非convelx问题上提供全球最佳性保证,例如,有障碍的情景。为了在两个世界中取得最佳效果,我们引入一个新的规划者,即BITKOMO(BIT*),它将无症状最佳的批量知情树(BIT*)规划者与K-Order Markov最佳轨道优化框架(KOMO)融合在一起。我们的规划者随时会保持BIT* 所提供的同样的最佳性保证,同时也会利用KOMO轨迹优化的快速趋同。我们实验性地评估我们的操纵方案者,这些操纵方案涉及高维度配置空间,多达两个7-DoF操纵器、障碍和狭窄通道。BITKOMO(BITMO)比KOMO(KOMO)表现得更好,即使KOMO(KOMO)失败时也能超越最佳解决办法。