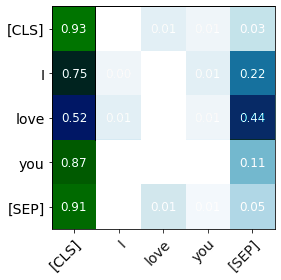
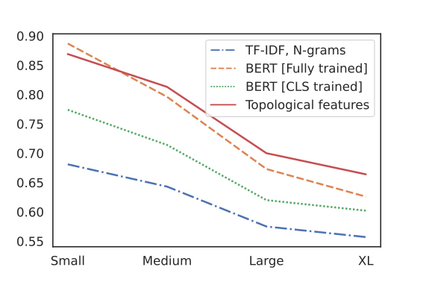
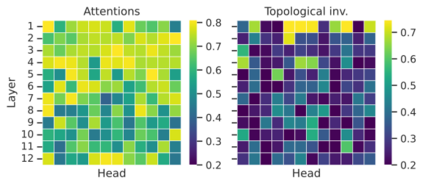
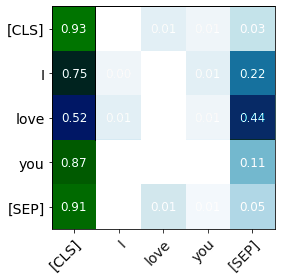
The impressive capabilities of recent generative models to create texts that are challenging to distinguish from the human-written ones can be misused for generating fake news, product reviews, and even abusive content. Despite the prominent performance of existing methods for artificial text detection, they still lack interpretability and robustness towards unseen models. To this end, we propose three novel types of interpretable topological features for this task based on Topological Data Analysis (TDA) which is currently understudied in the field of NLP. We empirically show that the features derived from the BERT model outperform count- and neural-based baselines up to 10\% on three common datasets, and tend to be the most robust towards unseen GPT-style generation models as opposed to existing methods. The probing analysis of the features reveals their sensitivity to the surface and syntactic properties. The results demonstrate that TDA is a promising line with respect to NLP tasks, specifically the ones that incorporate surface and structural information.
翻译:最近为创建与人造文本有挑战性的案文而建立的基因模型的惊人能力,可被滥用于制作假新闻、产品审查,甚至滥用内容。尽管现有人工文本探测方法表现突出,但它们仍然缺乏对不可见模型的可解释性和坚固性。为此,我们根据目前未在国家土地规划领域接受过研究的地形数据分析,为这项任务提出了三种新颖的可解释的地形特征。我们从经验上表明,从BERT模型得出的特征在三个通用数据集上超过10°C的计数和神经基线,在三个通用数据集上往往最强有力地对待看不见的GPT型生成模型,而不是现有方法。对特征的测试分析显示了其对表面和合成特性的敏感度。结果表明,在NLP任务方面,特别是包含地表和结构信息的模型,TDA是一个很有希望的线。