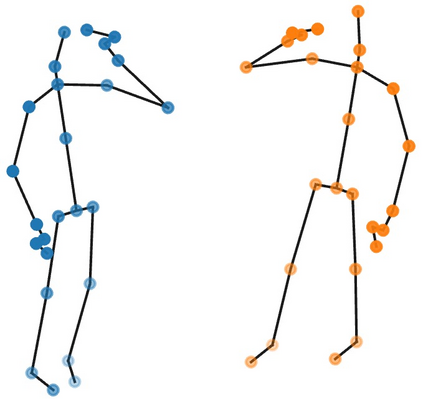
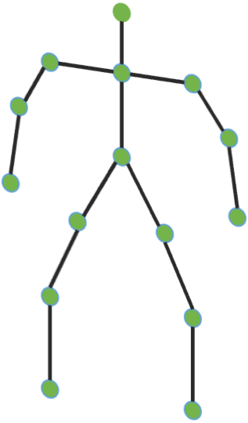
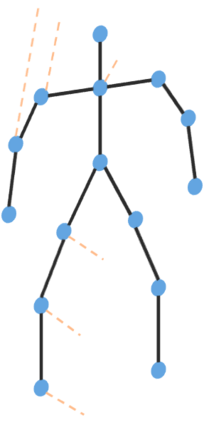
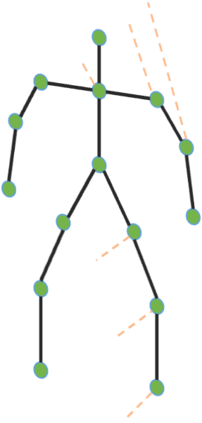
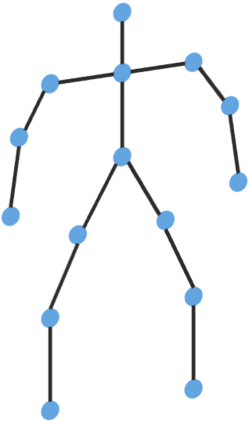
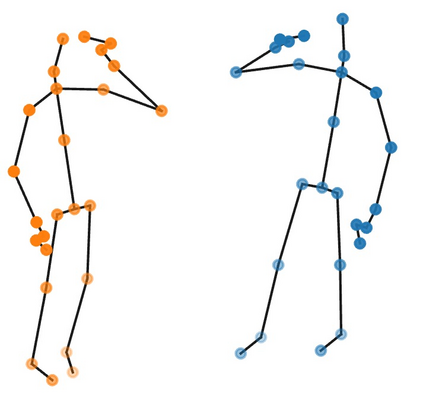
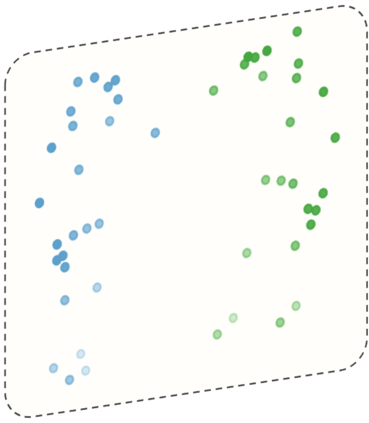
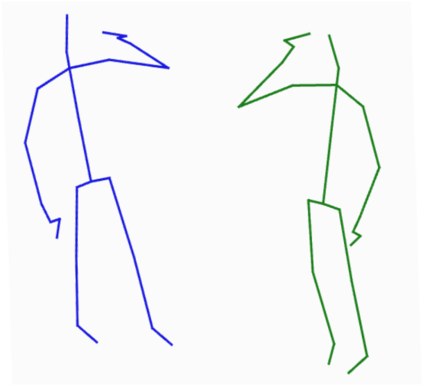
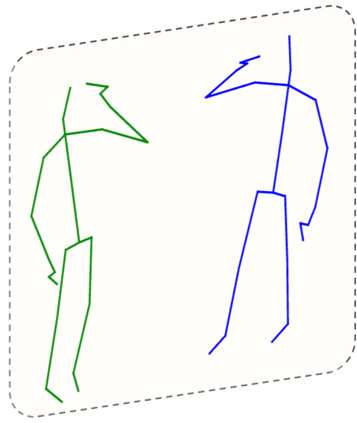
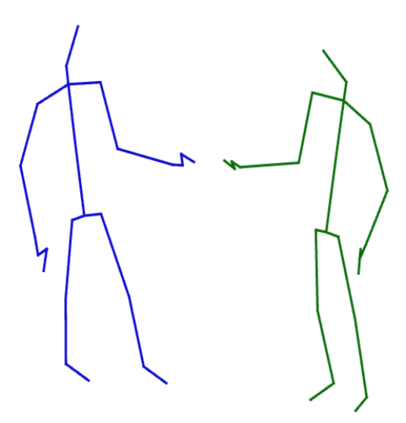
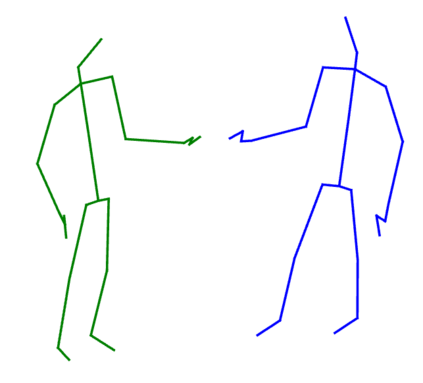
Graph Convolutional Network (GCN) outperforms previous methods in the skeleton-based human action recognition area, including human-human interaction recognition task. However, when dealing with interaction sequences, current GCN-based methods simply split the two-person skeleton into two discrete sequences and perform graph convolution separately in the manner of single-person action classification. Such operation ignores rich interactive information and hinders effective spatial relationship modeling for semantic pattern learning. To overcome the above shortcoming, we introduce a novel unified two-person graph representing spatial interaction correlations between joints. Also, a properly designed graph labeling strategy is proposed to let our GCN model learn discriminant spatial-temporal interactive features. Experiments show accuracy improvements in both interactions and individual actions when utilizing the proposed two-person graph topology. Finally, we propose a Two-person Graph Convolutional Network (2P-GCN). The proposed 2P-GCN achieves state-of-the-art results on four benchmarks of three interaction datasets, SBU, NTU-RGB+D, and NTU-RGB+D 120.
翻译:然而,在处理互动序列时,目前以GCN为基础的方法只是将两个人的骨架分成两个独立的序列,以单人行动分类的方式进行图解演化。这种操作忽视了丰富的互动信息,并阻碍了为语义模式学习而进行有效的空间关系建模。为了克服上述缺陷,我们引入了一个新型的、统一的、代表联合之间空间互动关系的双人统一图表。此外,还提出一个设计得当的图形标签战略,让我们的GCN模型学习不同时空空间互动特征。实验显示,在使用拟议的两人图表表层学时,互动和个人行动的准确性都有提高。最后,我们提议建立一个两人的图象革命网络(2P-GCN)。拟议的2P-GCN在三个互动数据集(SBU、NTU-RGB+D和NTU-RGB+D)的4个基准上实现最新结果。