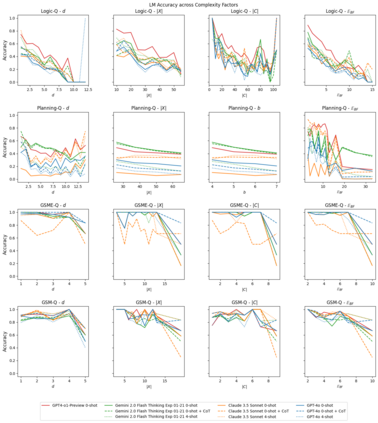
Recently, a large amount of work has focused on improving large language models' (LLMs') performance on reasoning benchmarks such as math and logic. However, past work has largely assumed that tasks are well-defined. In the real world, queries to LLMs are often underspecified, only solvable through acquiring missing information. We formalize this as a constraint satisfaction problem (CSP) with missing variable assignments. Using a special case of this formalism where only one necessary variable assignment is missing, we can rigorously evaluate an LLM's ability to identify the minimal necessary question to ask and quantify axes of difficulty levels for each problem. We present QuestBench, a set of underspecified reasoning tasks solvable by asking at most one question, which includes: (1) Logic-Q: Logical reasoning tasks with one missing proposition, (2) Planning-Q: PDDL planning problems with initial states that are partially-observed, (3) GSM-Q: Human-annotated grade school math problems with one missing variable assignment, and (4) GSME-Q: a version of GSM-Q where word problems are translated into equations by human annotators. The LLM is tasked with selecting the correct clarification question(s) from a list of options. While state-of-the-art models excel at GSM-Q and GSME-Q, their accuracy is only 40-50% on Logic-Q and Planning-Q. Analysis demonstrates that the ability to solve well-specified reasoning problems may not be sufficient for success on our benchmark: models have difficulty identifying the right question to ask, even when they can solve the fully specified version of the problem. Furthermore, in the Planning-Q domain, LLMs tend not to hedge, even when explicitly presented with the option to predict ``not sure.'' This highlights the need for deeper investigation into models' information acquisition capabilities.
翻译:暂无翻译