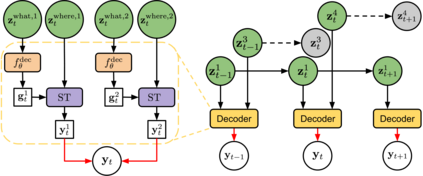
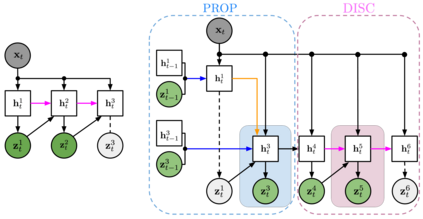
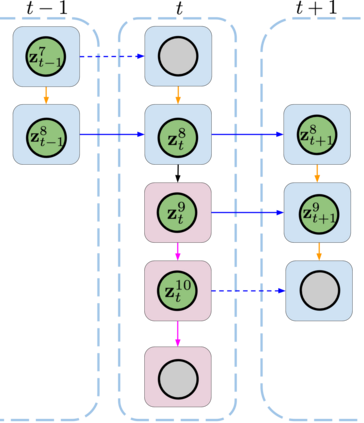
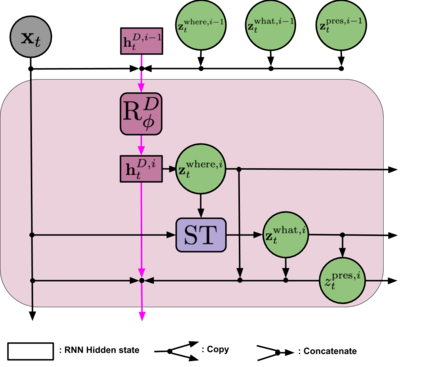
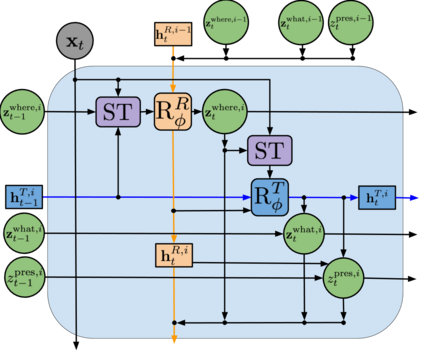
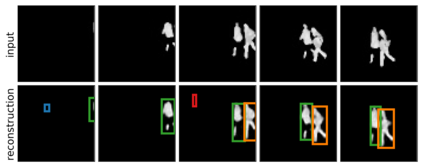
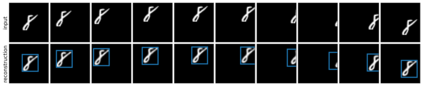
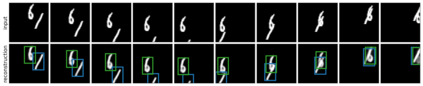
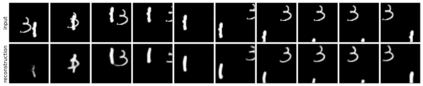
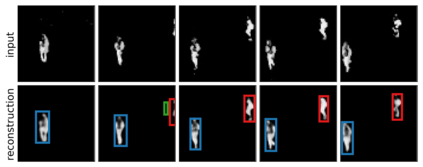
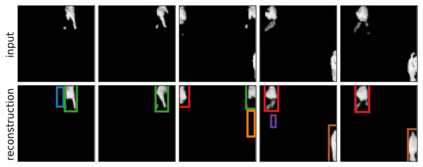
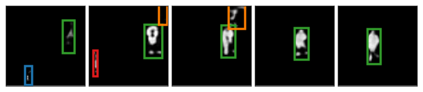
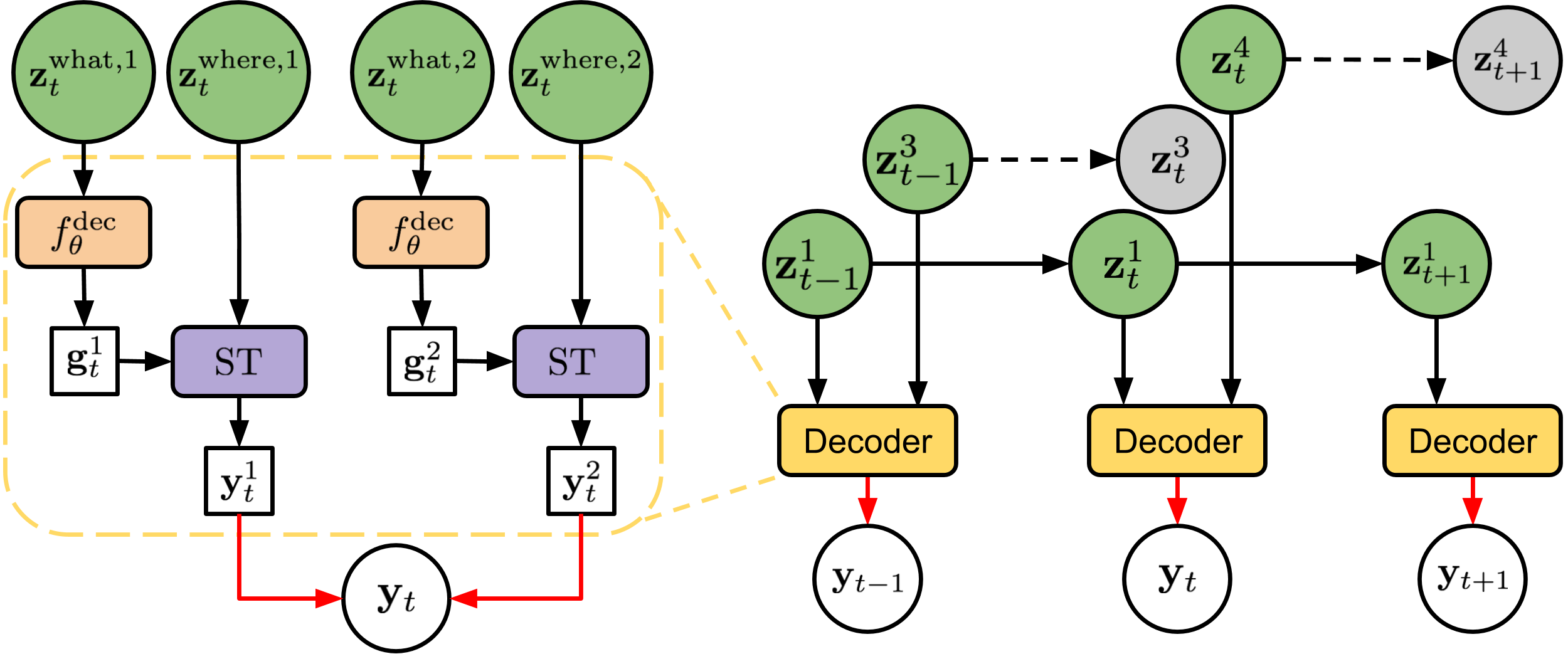
We present Sequential Attend, Infer, Repeat (SQAIR), an interpretable deep generative model for videos of moving objects. It can reliably discover and track objects throughout the sequence of frames, and can also generate future frames conditioning on the current frame, thereby simulating expected motion of objects. This is achieved by explicitly encoding object presence, locations and appearances in the latent variables of the model. SQAIR retains all strengths of its predecessor, Attend, Infer, Repeat (AIR, Eslami et. al., 2016), including learning in an unsupervised manner, and addresses its shortcomings. We use a moving multi-MNIST dataset to show limitations of AIR in detecting overlapping or partially occluded objects, and show how SQAIR overcomes them by leveraging temporal consistency of objects. Finally, we also apply SQAIR to real-world pedestrian CCTV data, where it learns to reliably detect, track and generate walking pedestrians with no supervision.
翻译:我们展示了可解释的移动对象视频的深深层次基因模型(SQAIR),它可以可靠地发现和跟踪整个框架序列中的物体,还可以在目前框架上生成未来框架,从而模拟预期物体运动。这是通过在模型的潜伏变量中明确编码对象存在、位置和外观来实现的。SQAIR保留其前身、显示、导出、重复(AIR, Eslami等人,2016年)的所有优点,包括以不受监督的方式学习,并解决其缺点。我们使用移动的多MNIST数据集来显示AIR在探测重叠或部分隐蔽物体方面的局限性,并展示SQAIR如何通过利用物体的时间一致性来克服这些局限性。最后,我们还将SQAIR应用到真实世界行人闭路数据,在那里学会在没有监督的情况下可靠地检测、跟踪和生成行人行人。