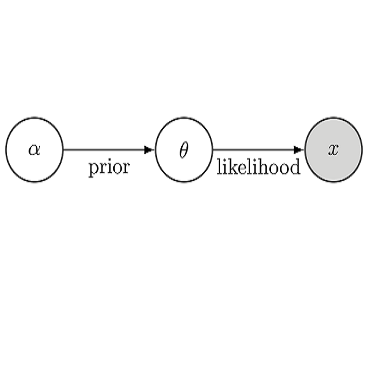
Reinforcement learning (RL) is frequently employed in fine-tuning large language models (LMs), such as GPT-3, to penalize them for undesirable features of generated sequences, such as offensiveness, social bias, harmfulness or falsehood. The RL formulation involves treating the LM as a policy and updating it to maximise the expected value of a reward function which captures human preferences, such as non-offensiveness. In this paper, we analyze challenges associated with treating a language model as an RL policy and show how avoiding those challenges requires moving beyond the RL paradigm. We start by observing that the standard RL approach is flawed as an objective for fine-tuning LMs because it leads to distribution collapse: turning the LM into a degenerate distribution. Then, we analyze KL-regularised RL, a widely used recipe for fine-tuning LMs, which additionally constrains the fine-tuned LM to stay close to its original distribution in terms of Kullback-Leibler (KL) divergence. We show that KL-regularised RL is equivalent to variational inference: approximating a Bayesian posterior which specifies how to update a prior LM to conform with evidence provided by the reward function. We argue that this Bayesian inference view of KL-regularised RL is more insightful than the typically employed RL perspective. The Bayesian inference view explains how KL-regularised RL avoids the distribution collapse problem and offers a first-principles derivation for its objective. While this objective happens to be equivalent to RL (with a particular choice of parametric reward), there exist other objectives for fine-tuning LMs which are no longer equivalent to RL. That observation leads to a more general point: RL is not an adequate formal framework for problems such as fine-tuning language models. These problems are best viewed as Bayesian inference: approximating a pre-defined target distribution.
翻译:强化学习( RL) 经常用于微调大型语言模型( LM), 比如 GPT 3 ), 以生成的序列的不可取特征来惩罚它们, 比如攻击性、 社会偏向、 伤害性或虚假。 RL 配方包括将 LM 作为一种政策, 并更新它, 以最大化奖励功能的预期值, 从而捕捉人的偏好, 比如非攻击性。 在本文中, 我们分析与将语言模型作为 RL 政策相关的挑战, 并显示如何避免这些挑战需要超越 RL 模式。 我们首先看到, 标准 RL 方法作为微调 LM 的目标, 因为它导致发行发行失败: 将 LM 变成一个扭曲的 。 然后, 我们分析 KL 常规的 RLL, 这是用来微调 LM 最佳LM 的配方, 这进一步制约了 LM 精调 LM, 以保持与 KRFER 语言( KL) 的原始分布。 我们显示, KL 常规RL 的调与 的比 直观性框架更接近性框架 。