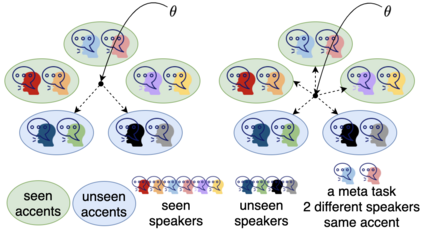
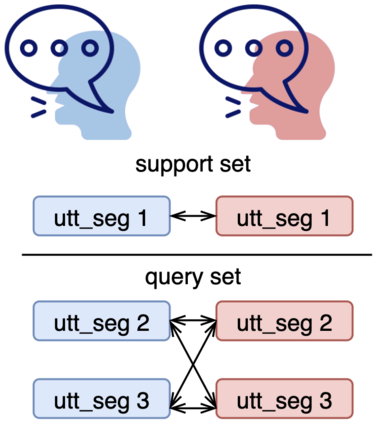
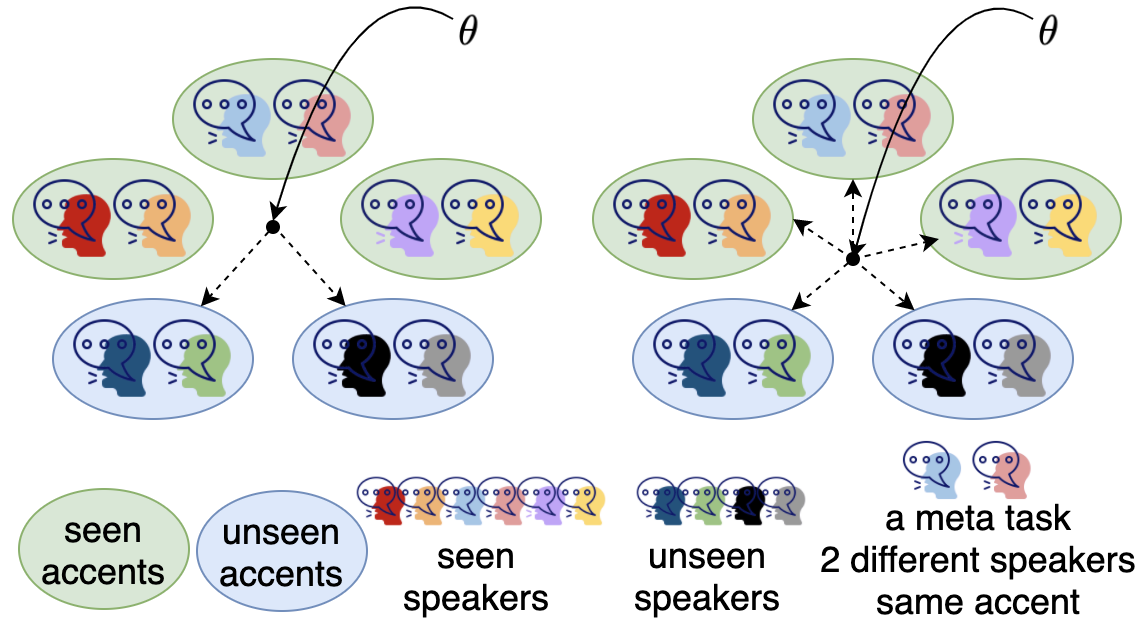
Speech separation is a problem in the field of speech processing that has been studied in full swing recently. However, there has not been much work studying a multi-accent speech separation scenario. Unseen speakers with new accents and noise aroused the domain mismatch problem which cannot be easily solved by conventional joint training methods. Thus, we applied MAML and FOMAML to tackle this problem and obtained higher average Si-SNRi values than joint training on almost all the unseen accents. This proved that these two methods do have the ability to generate well-trained parameters for adapting to speech mixtures of new speakers and accents. Furthermore, we found out that FOMAML obtains similar performance compared to MAML while saving a lot of time.
翻译:语音分离是最近全面研究的语音处理领域的一个问题,然而,研究多语种语言分离方案的工作不多,使用新口音和噪音的不见的发言者引发了域错配问题,而传统联合培训方法无法轻易解决。因此,我们运用MAML和FOMAMM来解决这一问题,并获得了比几乎所有看不见口音的联合培训更高的平均Si-SNRI价值观。这证明这两种方法确实有能力产生训练有素的参数,以适应新口音和口音的语音组合。此外,我们发现FOMAML在节省大量时间的同时,取得了与MAML相似的性能。