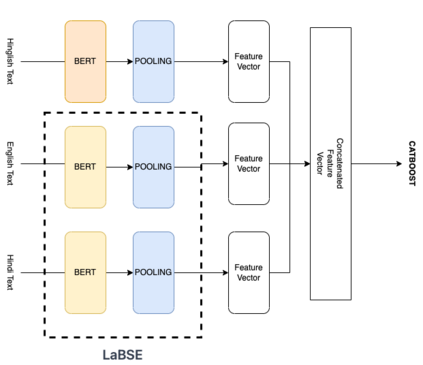
This paper describes the system description for the HinglishEval challenge at INLG 2022. The goal of this task was to investigate the factors influencing the quality of the code-mixed text generation system. The task was divided into two subtasks, quality rating prediction and annotators disagreement prediction of the synthetic Hinglish dataset. We attempted to solve these tasks using sentence-level embeddings, which are obtained from mean pooling the contextualized word embeddings for all input tokens in our text. We experimented with various classifiers on top of the embeddings produced for respective tasks. Our best-performing system ranked 1st on subtask B and 3rd on subtask A.
翻译:本文描述了INLG 2022 HinglishEval 挑战的系统描述。 任务的目的是调查影响编码混合文本生成系统质量的因素。 任务分为两个子任务, 质量评级预测和批注员对合成Hinglish数据集的分歧预测。 我们试图使用判决级嵌入来完成这些任务, 这些嵌入来自我们文本中所有输入符号的背景化字嵌入。 我们在为各自任务制作的嵌入层顶端试验了各种分类师。 我们的最佳系统在子任务B上排第1,在子任务A上排第3位。