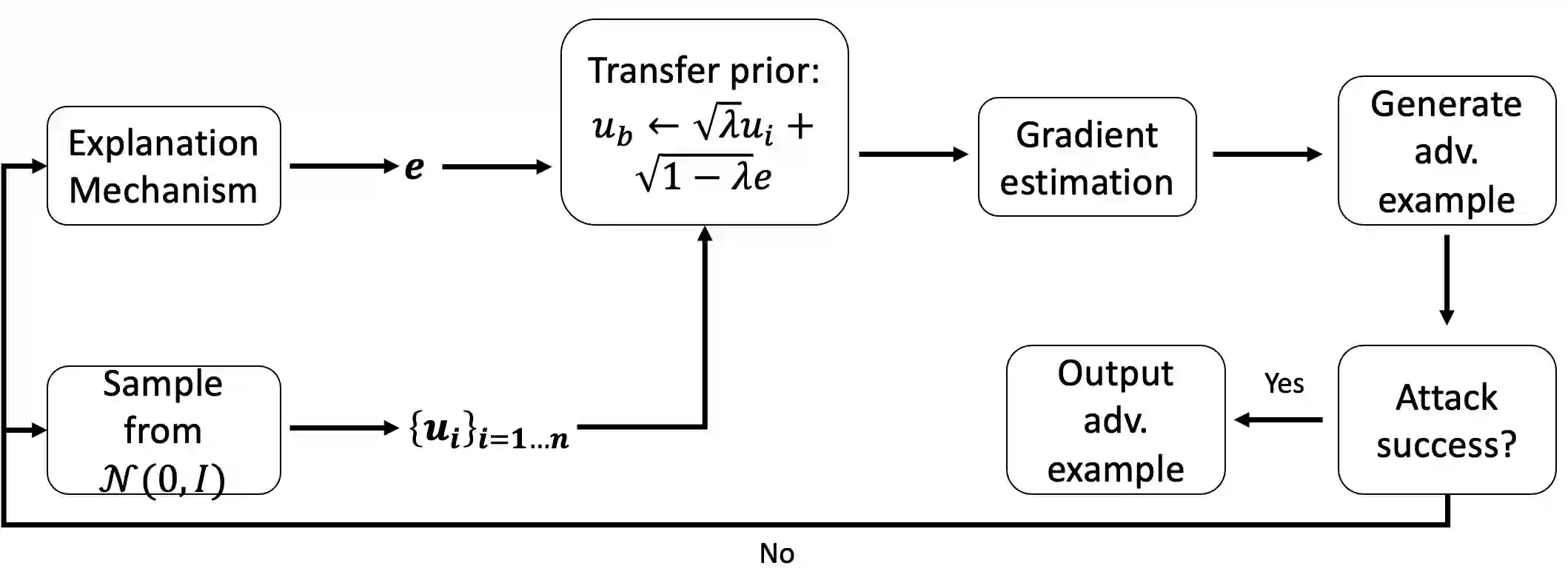
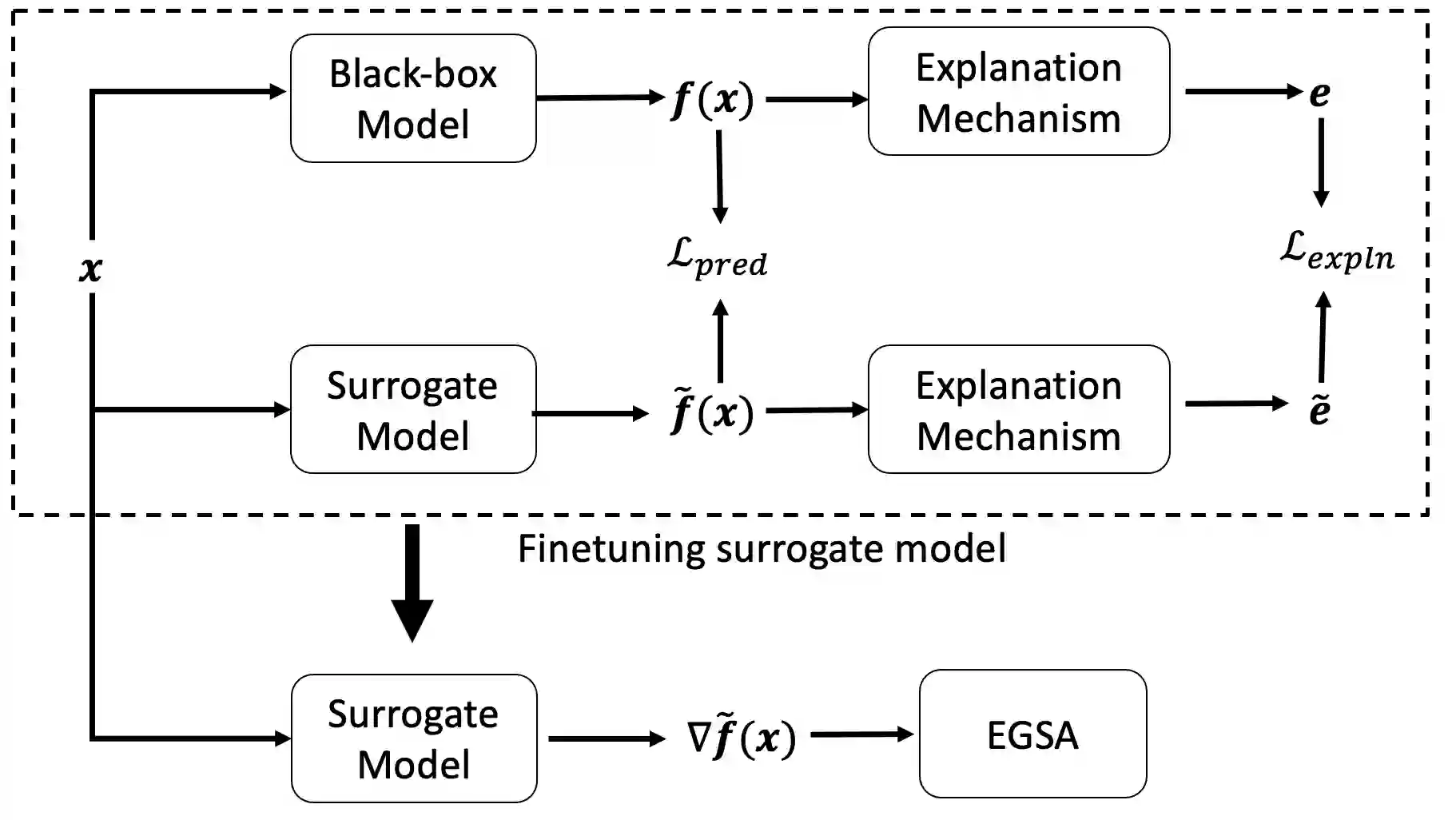
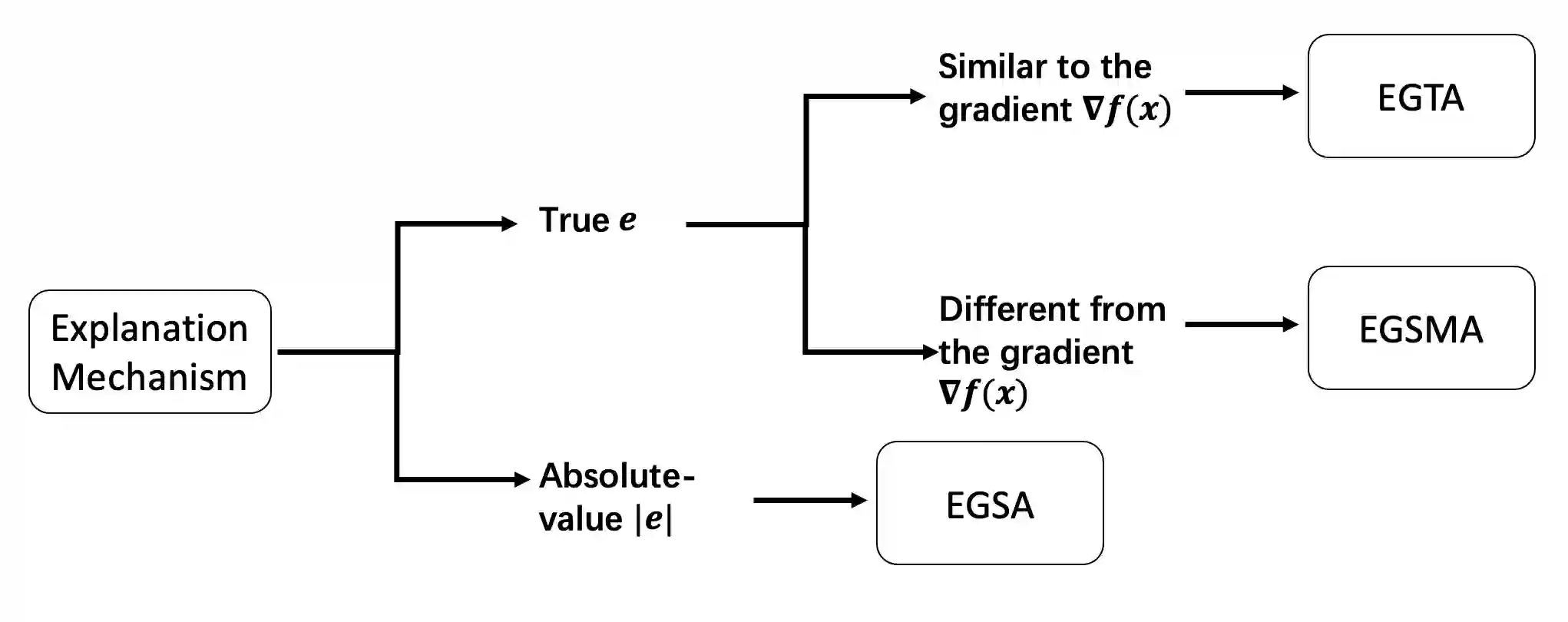
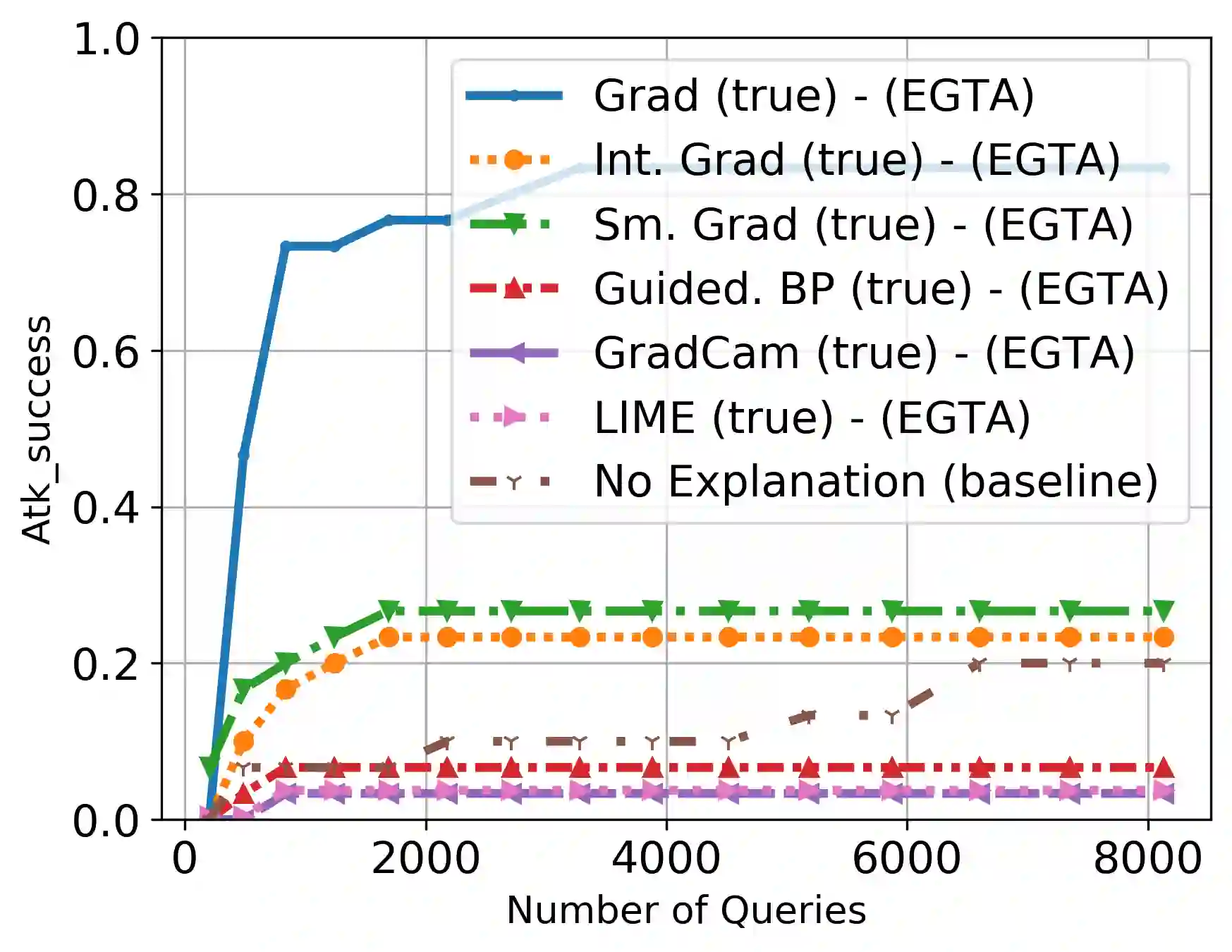
A variety of explanation methods have been proposed in recent years to help users gain insights into the results returned by neural networks, which are otherwise complex and opaque black-boxes. However, explanations give rise to potential side-channels that can be leveraged by an adversary for mounting attacks on the system. In particular, post-hoc explanation methods that highlight input dimensions according to their importance or relevance to the result also leak information that weakens security and privacy. In this work, we perform the first systematic characterization of the privacy and security risks arising from various popular explanation techniques. First, we propose novel explanation-guided black-box evasion attacks that lead to 10 times reduction in query count for the same success rate. We show that the adversarial advantage from explanations can be quantified as a reduction in the total variance of the estimated gradient. Second, we revisit the membership information leaked by common explanations. Contrary to observations in prior studies, via our modified attacks we show significant leakage of membership information (above 100% improvement over prior results), even in a much stricter black-box setting. Finally, we study explanation-guided model extraction attacks and demonstrate adversarial gains through a large reduction in query count.
翻译:近年来提出了各种解释方法,以帮助用户深入了解神经网络(这些网络本来是复杂和不透明的黑盒)所返回的结果;然而,解释产生了潜在的侧道,对手可以利用这些侧道来发动攻击系统。特别是,根据输入的重要性或对结果的相关性来强调输入层面的热后解释方法,还泄漏了削弱安全和隐私的信息。在这项工作中,我们对各种大众解释技术产生的隐私和安全风险进行了首次系统描述。首先,我们提出了新颖的解释性黑盒规避攻击,导致相同成功率的查询数减少10倍。我们表明,解释的对抗性优势可以量化为估计梯度总差异的减少。第二,我们重新审视由共同解释泄露的会籍信息。与先前研究中的意见相反,我们通过修改的攻击,我们发现会籍信息大量泄漏(比以前的结果改进了100%),甚至在更加严格的黑盒设置中也是如此。最后,我们研究了解释性驱逐模式攻击的模型,并通过大幅削减计数来显示对抗性收益。