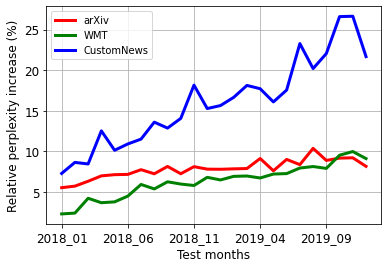
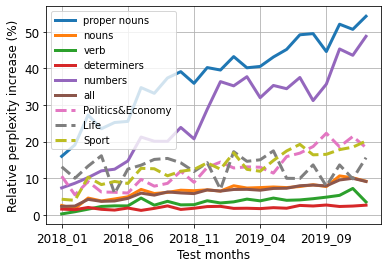
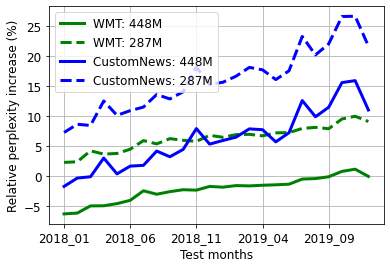
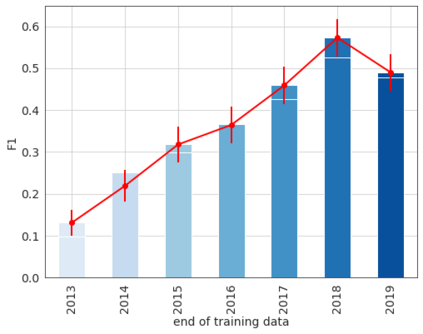
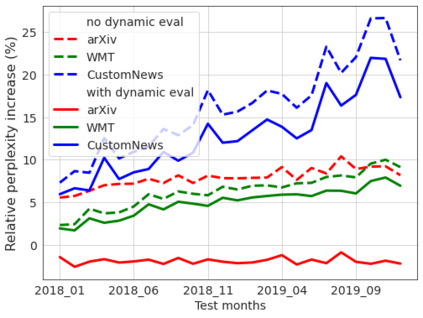
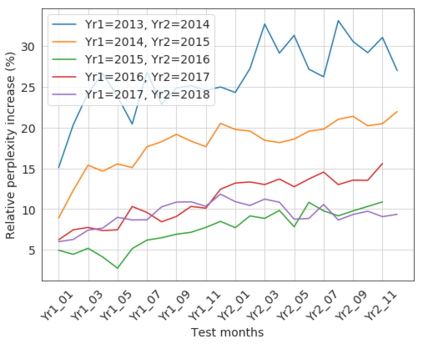
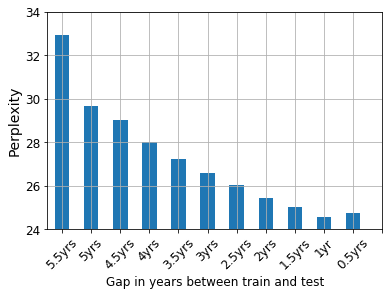
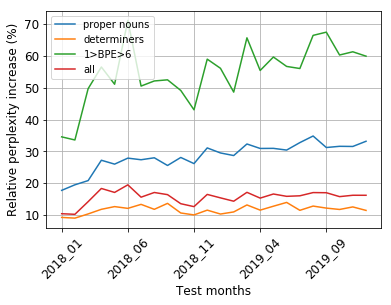
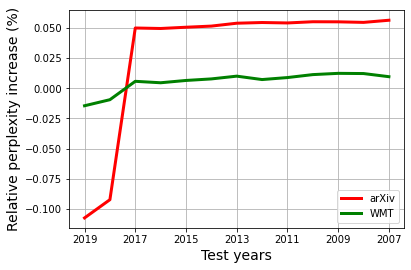
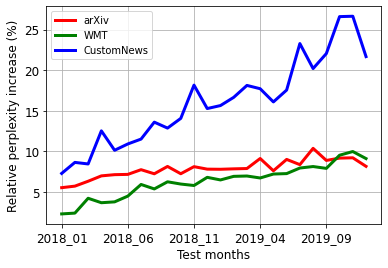
Our world is open-ended, non-stationary, and constantly evolving; thus what we talk about and how we talk about it change over time. This inherent dynamic nature of language contrasts with the current static language modelling paradigm, which trains and evaluates models on utterances from overlapping time periods. Despite impressive recent progress, we demonstrate that Transformer-XL language models perform worse in the realistic setup of predicting future utterances from beyond their training period, and that model performance becomes increasingly worse with time. We find that, while increasing model size alone -- a key driver behind recent progress -- does not solve this problem, having models that continually update their knowledge with new information can indeed mitigate this performance degradation over time. Hence, given the compilation of ever-larger language modelling datasets, combined with the growing list of language-model-based NLP applications that require up-to-date factual knowledge about the world, we argue that now is the right time to rethink the static way in which we currently train and evaluate our language models, and develop adaptive language models that can remain up-to-date with respect to our ever-changing and non-stationary world. We publicly release our dynamic, streaming language modelling benchmarks for WMT and arXiv to facilitate language model evaluation that takes temporal dynamics into account.
翻译:我们的世界是开放的、非静止的,并不断演变;因此,我们谈论的是什么以及我们谈论它的方式随着时间的推移而改变;语言的这种内在动态性质与目前静态的语言建模模式模式形成鲜明对比,后者培训和评价重叠时期的发音模式。尽管最近取得了令人印象深刻的进展,但我们证明,在现实地预测未来在培训期之后的发音方面,变异-XL语言模式表现更差,而且随着时间的流逝,模型性能也越来越差。我们发现,虽然仅靠模型规模的扩大本身 -- -- 近期进展背后的一个关键驱动因素 -- -- 并不能解决这个问题,但拥有不断以新信息更新知识的模型确实能够减少这种性能退化。因此,鉴于正在汇编的日多语言建模数据集,加上不断增长的基于语言建模的NLP应用程序清单,需要最新的世界事实知识,因此我们现在应该重新思考我们目前培训和评价语言模式的静态方式,并发展适应性语言模型,这些模式能够跟上我们不断变化和非静止的动态语言模型,从而将我们公开地公布一个动态的版本。