摘要
自然语言处理(NLP)是人工智能的一个子领域,其重点是使计算机能够理解和处理人类语言。在过去的五年里,我们见证了NLP在机器翻译、问答和基于深度学习的机器阅读理解等任务上的快速发展,以及海量的带注释和未带注释的数据。本文将从建模、学习和推理三个方面综述基于神经网络的神经语言处理框架(neural NLP)的最新进展。在建模部分,我们将描述几种基本的基于神经网络的建模范例,如单词嵌入、句子嵌入和序列到序列的建模,这些在现代NLP引擎中被广泛使用。在学习部分,我们将介绍广泛使用的NLP模型的学习方法,包括监督学习、半监督学习和无监督学习;多任务学习;迁移学习;和主动学习。我们认为推理是神经NLP的一个新的和令人兴奋的方向,但它还没有被很好地解决。在推理部分,我们将回顾推理机制,包括知识,现有的非神经推理方法,和新的神经推理方法。我们在本文中强调推理的重要性,因为它对于建立可解释的和知识驱动的神经网络规划模型来处理复杂的任务是很重要的。在本文的最后,我们将简要概述我们对神经语言处理的未来发展方向的思考。
介绍
自然语言处理(Natural Language Processing, NLP)是人工智能(AI)的一个重要分支,通过自然语言研究人与计算机之间的交互。它研究单词、短语、句子和文档的意义表达的基础技术,以及句法和语义处理(如断句、句法分析器和语义解析)的基础技术,并开发诸如机器翻译(MT)、问答(QA)、信息检索、对话、文本生成和推荐系统等应用程序。NLP对于搜索引擎、客户支持系统、商业智能和语音助手至关重要。
NLP的历史可以追溯到20世纪50年代。在NLP研究之初,我们使用基于规则的方法来构建NLP系统,包括单词/句子分析、QA和MT。这些由专家编辑的规则被用于从MT开始的各种NLP任务的算法中。通常,设计规则需要大量的人力。此外,当规则数量很大时,很难组织和管理规则。20世纪90年代,随着互联网的快速发展,出现了大量的数据,这使得统计学习方法可以用于处理NLP任务。使用人工设计的特征,统计学习模型通过使用标记/挖掘数据学习。统计学习方法为许多自然语言处理任务,特别是MT和搜索引擎技术带来了显著的改进。2012年,随着深度学习在ImageNet[1]对象识别和Switchboard[2]语音识别方面的成功,深度学习方法被引入到NLP中。深度学习方法比统计学习方法快得多,结果好得惊人。目前,基于神经网络的神经语言处理(以下简称神经语言处理)框架已经达到了新的质量水平,并且已经成为处理神经语言处理任务的主要方法,例如MT、机器阅读理解(MRC)、聊天机器人等等。例如,微软的Bible系统在2017年MT研讨会的中英新闻翻译任务中就取得了能和人媲美的结果。微软亚洲研究院(MSRA)的R-NET和NLNet在斯坦福问题回答数据集(小组)评估任务中,在精确匹配(EM)得分和模糊匹配(F1)得分上都取得了人机质量结果。最近,生成式预训练(GPT)[3]、来自 Transformers的双向编码器表示(BERT)[4]和XLNet[5]等预训练模型在多个NLP任务中显示了强大的能力。神经NLP框架在有大量标记数据用于学习神经模型的监督任务中工作得很好,但在资源有限或没有标记数据的低资源任务中仍然表现不佳。
建模
NLP系统使用自然语言句子并生成一个类类型(用于分类任务)、一个标签序列(用于序列标记任务)或另一个句子(用于QA、对话、自然语言生成和MT)。要应用神经语言处理方法,需要解决以下两个关键问题: (1)在神经网络中对自然语言句子(词的序列)进行编码。 (2)生成一个标签序列或另一个自然语言句子。 从这两个方面,本节将介绍几种常用的神经网络语言处理模型,包括字嵌入、句子嵌入和序列到序列的建模。单词嵌入将输入句子中的单词映射成连续的空间向量。 基于“嵌入”这个词,复杂网络如递归神经网络(RNNs)卷积神经网络(CNNs)和自注意力网络可以用于特征提取,考虑到整个句子的上下文信息构建嵌入环境敏感词,句子的或集成所有的信息来构造句子嵌入。上下文感知词嵌入可用于序列标记任务,如词性标记(POS)和命名实体识别(NER),句子嵌入可用于句子级任务,如情绪分析和意译分类。句子嵌入也可以作为另一个RNN或自注意网络的输入,生成另一个序列,形成序列-序列建模的编解码框架。给定一个输入句子,序列到序列的建模可以用来生成一个问题的答案(即问答任务)或翻译成另一种语言(即机器翻译任务)。
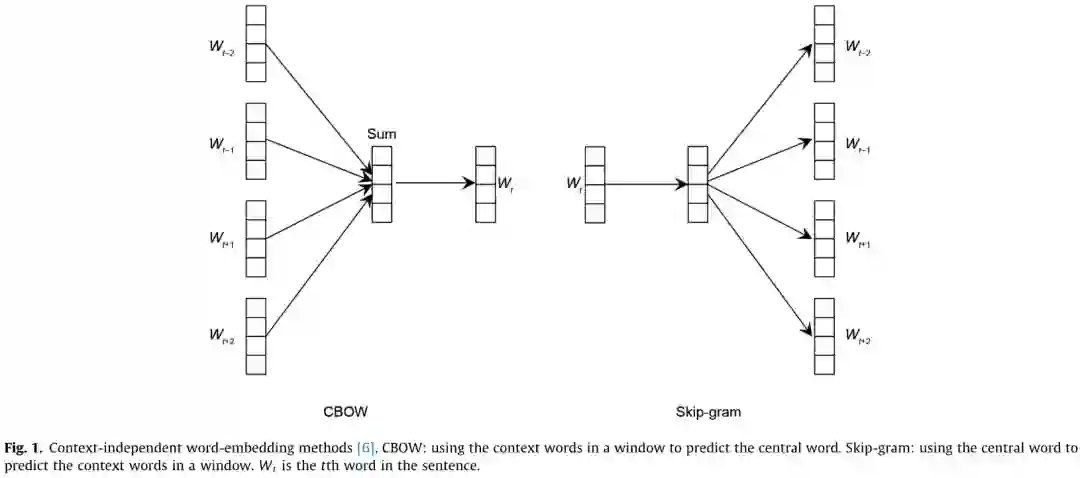
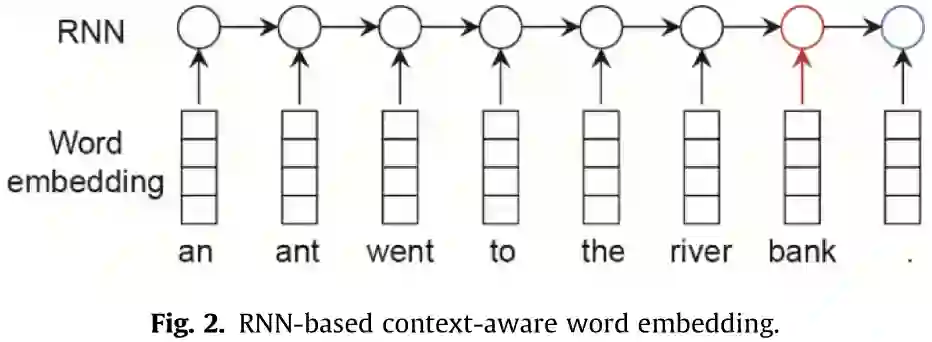
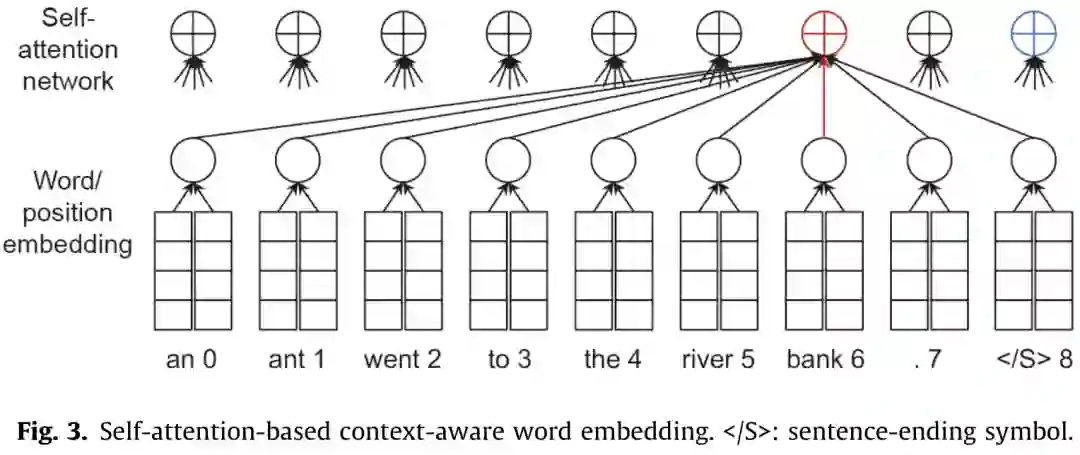
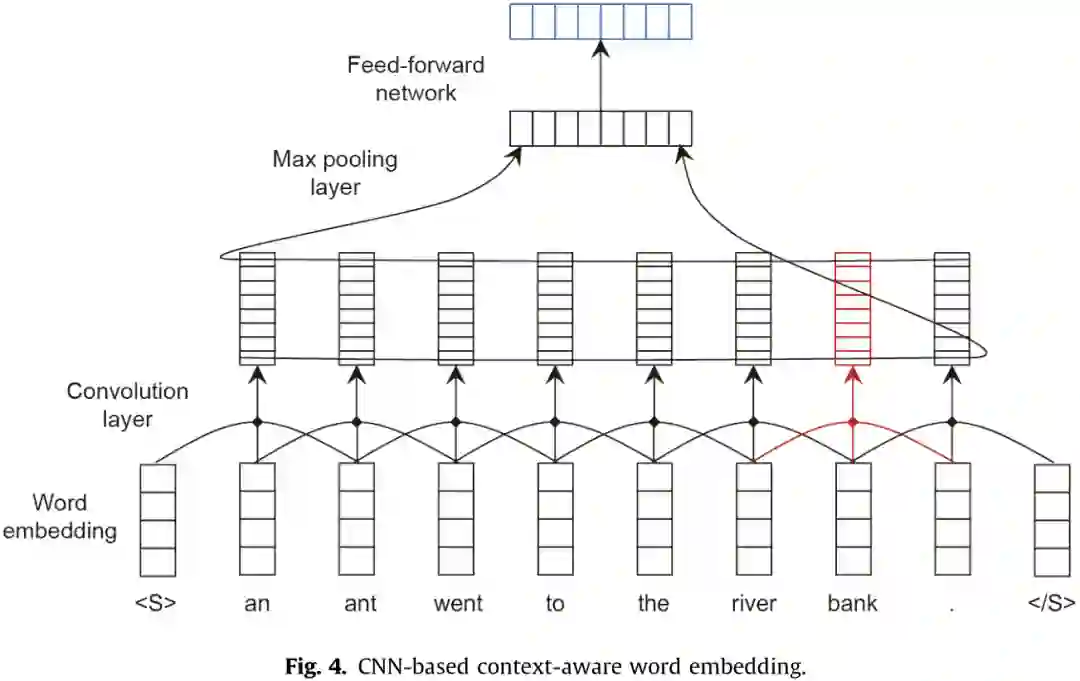
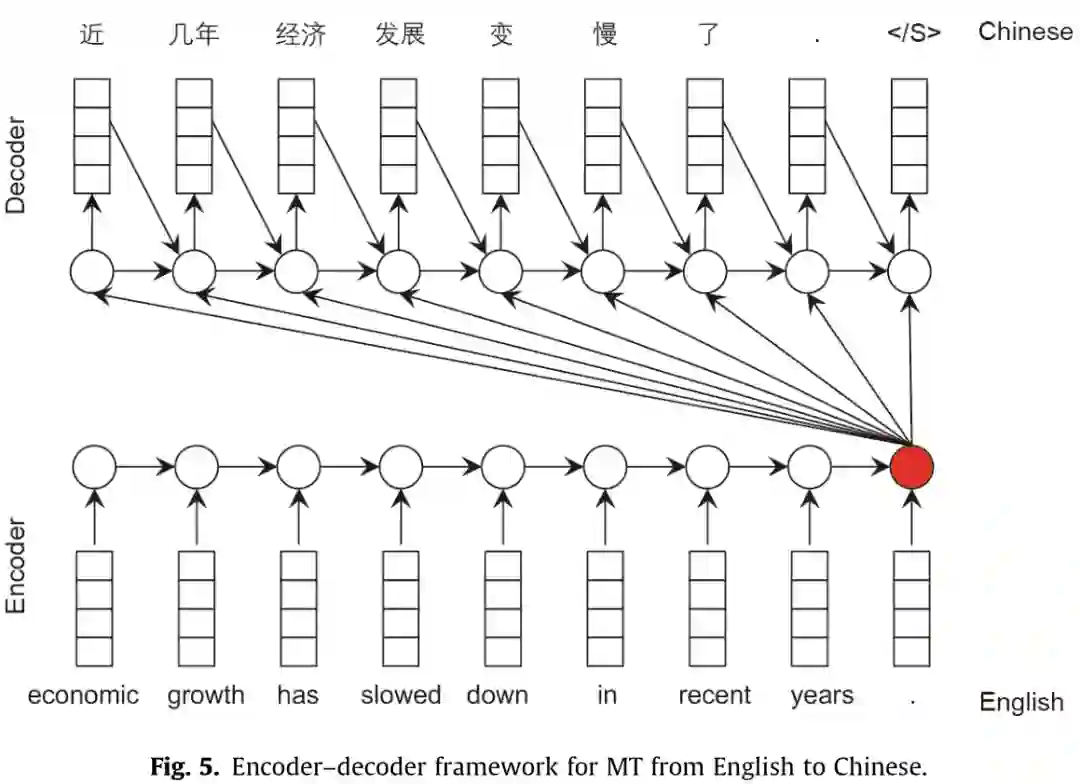
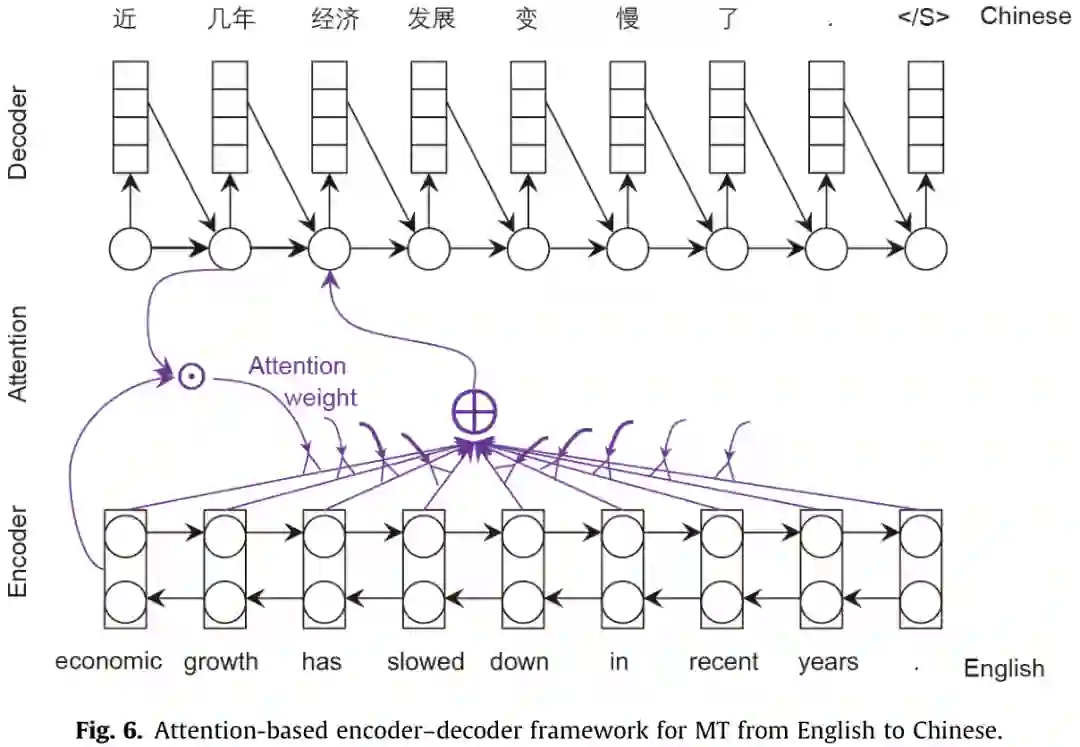
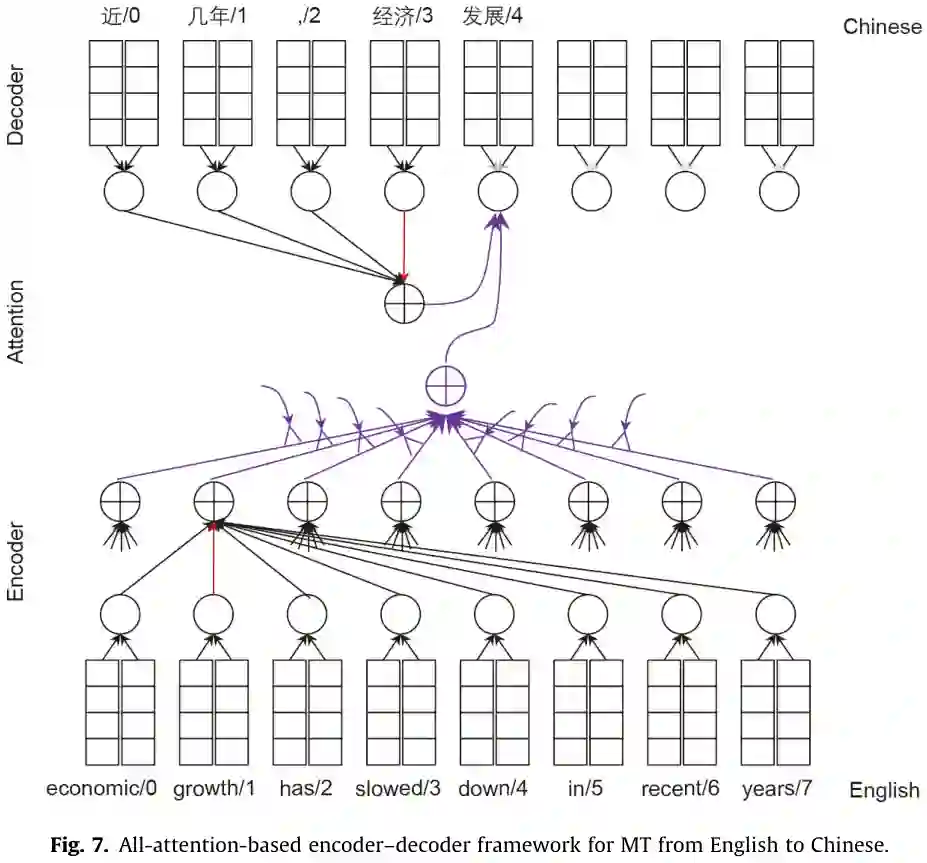
学习
目前已经提出了新的和有效的训练算法,以优化大量的参数在深度学习模型。在训练神经网络时,常用的方法是随机梯度下降(SGD)[18],它通常是基于[19]的反向传播方法。基于动量的SGD被提出是为了引入动量来加速训练过程。AdaGrad [20], AdaDelta [21], Adam [22], RMSProp方法尝试对不同的参数使用不同的学习比率,这进一步提高了效率,稳定了训练过程。当模型非常复杂时,并行训练方法被用来利用许多计算设备,甚至数百或数千台(中央处理单元、图形处理单元或现场可编程门阵列)。根据参数是否同步更新,分布式训练方法可以分为同步SGD和异步SGD。 除了一般的优化方法已经取得的进展外,针对特定的NLP任务提出了更好的训练方法。当大量的训练数据可用于资源丰富的任务时,使用监督学习方法,深度学习模型可以取得很好的性能。对于一些特定的任务,如具有大量并行数据的语言对(如英语和汉语)的MT,神经模型可以很好地完成,有时在共享任务中实现人的平等。然而,在许多NLP任务中,很难获得大量的标记数据。这类任务通常被称为低资源任务,包括对稀有语言的情绪分析MT。利用未标记数据对少量标记数据训练的模型进行增强,可以采用半监督学习方法。在没有任何标记数据的情况下,可以利用无监督学习方法来学习NLP模型。利用未标记数据的另一种方法是对模型进行预训练,通过迁移学习将这些模型转移到特定的任务中。除了利用任务内标记的数据,其他任务的标记数据也可以在多任务学习的帮助下使用。如果没有可用的数据,可以引入人力资源来使用主动学习创建学习数据,以便在给定的预算下最大化模型的性能。
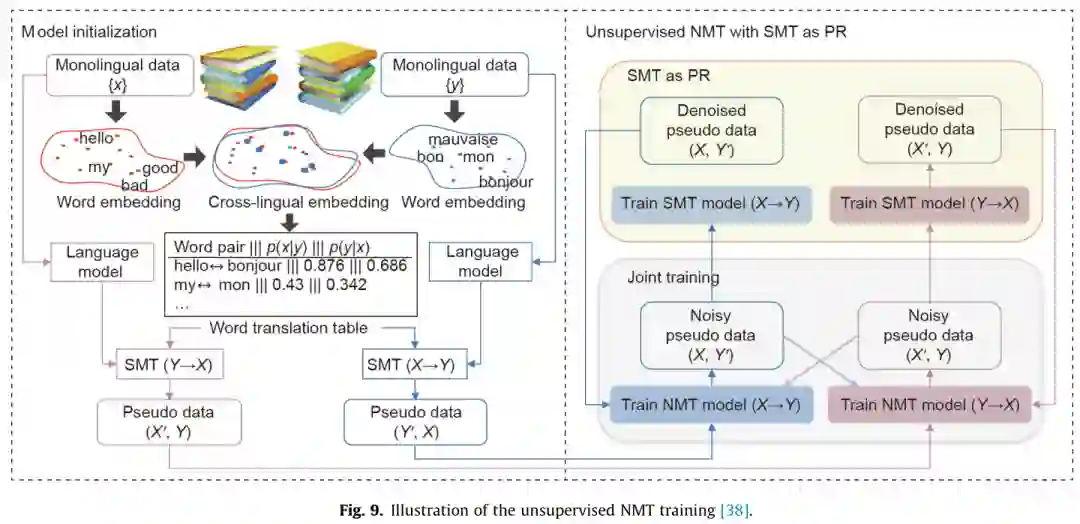
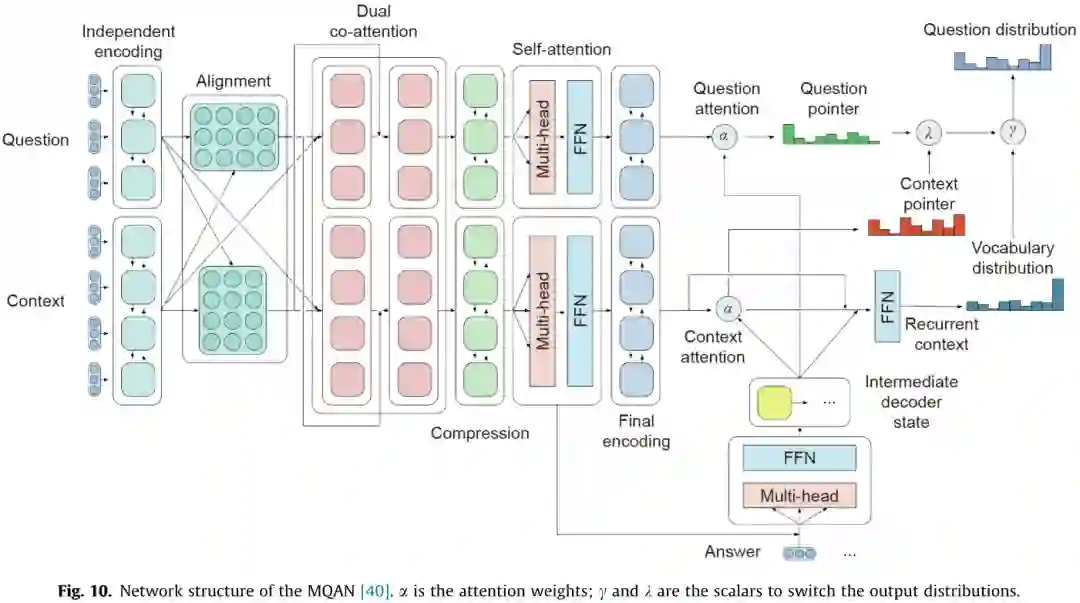
推理
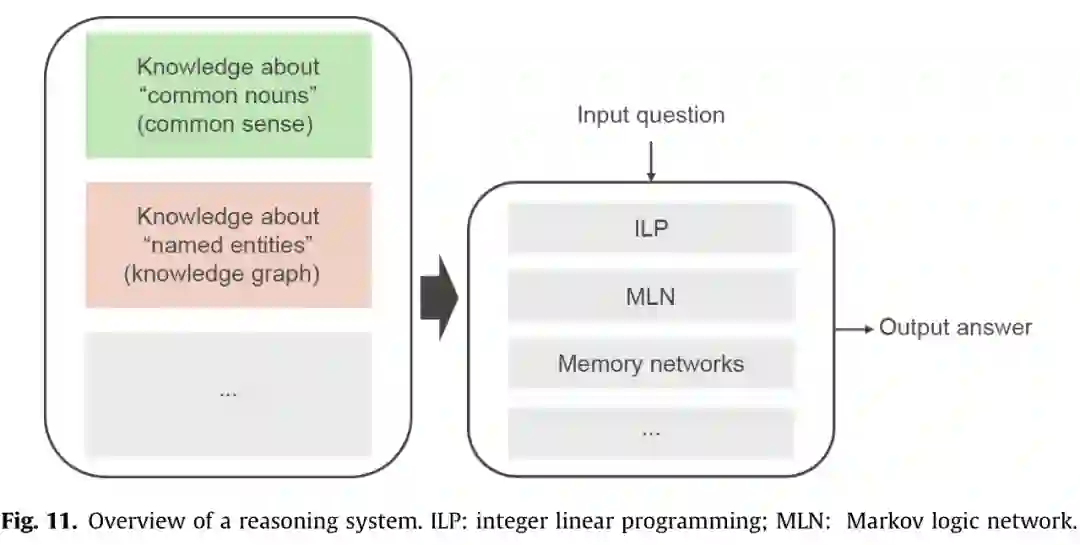
神经方法在许多NLP任务中取得了良好的进展,如MT和MRC。然而,他们仍然有一些未解决的问题。例如,大多数神经网络模型的行为就像一个黑盒子,它从来没有告诉我们一个系统是如何以及为什么会以这种方式解决了一个问题。此外,对于QA和对话系统这样的任务,仅仅了解输入话语的字面意义往往是不够的。为了生成正确的响应,可能还需要外部和/或上下文知识。为了建立这种可解释的和知识驱动的系统,推理是必要的。在本文中,我们将推理定义为一种机制,它可以通过使用推理技术操作现有知识来生成未见问题的答案。根据这一定义,推理系统(图11)应该包括两个部分:
-
知识,如知识图、常识、规则、从原始文本中提取的断言等;
-
一个推理引擎,通过操作现有的知识来生成问题的答案。
接下来,我们用两个例子来说明为什么推理对于NLP任务是重要的。
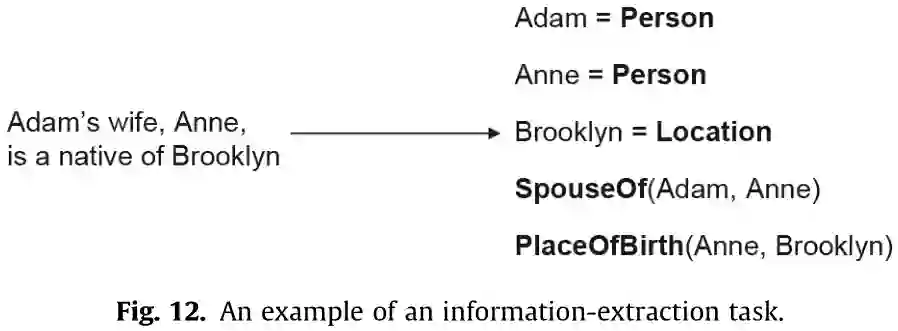
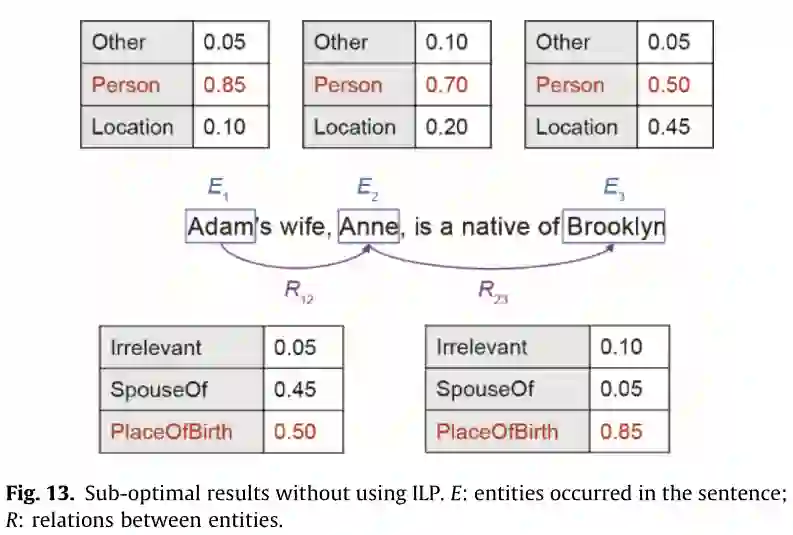
第一个例子是基于知识的QA任务。“比尔·盖茨的妻子是什么时候出生的?”, QA模型必须将其解析为生成答案的逻辑形式:
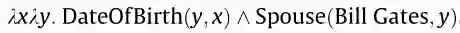
其中需要基于知识图谱的推理从这个问题开始,可以附加新的问题,例如:“他/她的工作是什么?”,为了回答这种上下文感知的问题,共指解析决定了他/她指的是谁。这也是一个推理的过程,需要一个常识,他只能指男人,她只能指女人。
第二个例子是一个对话任务。例如,如果一个用户说我现在很饿,更合适的回答应该是:让我向您推荐一些不错的餐馆,而不是让我推荐一些好电影给你。这也需要推理,因为对话系统应该知道饥饿会导致寻找餐馆而不是看电影的行为。在本节的剩余部分中,我们将首先介绍两种类型的知识:知识图谱和常识。接下来,我们将描述典型的推理方法,这些方法在自然语言处理领域已经或正在研究。