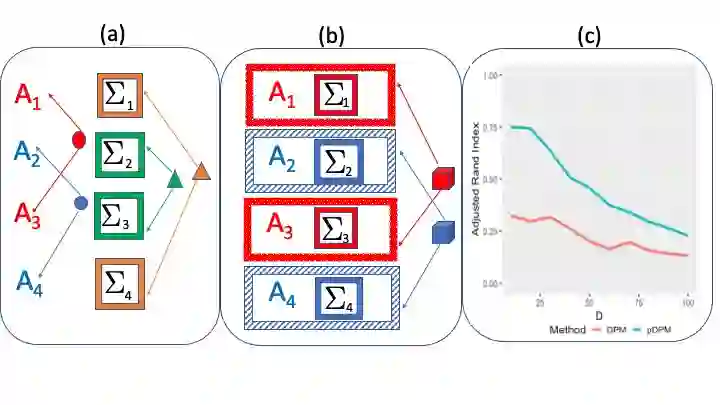
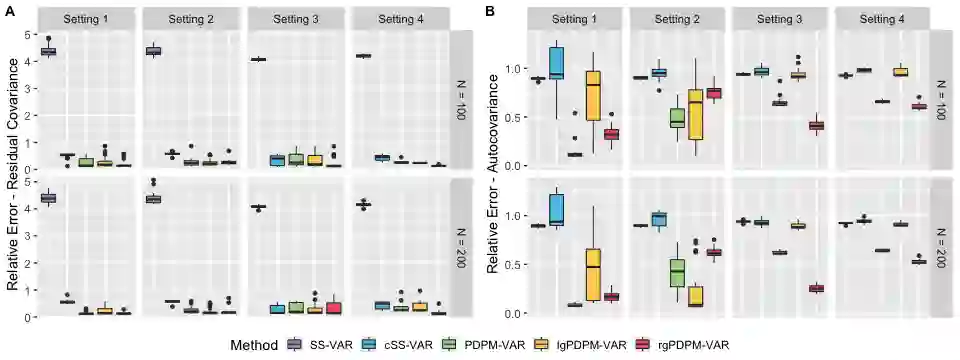
Bayesian non-parametric methods based on Dirichlet process mixtures have seen tremendous success in various domains and are appealing in being able to borrow information by clustering samples that share identical parameters. However, such methods can face hurdles in heterogeneous settings where objects are expected to cluster only along a subset of axes or where clusters of samples share only a subset of identical parameters. We overcome such limitations by developing a novel class of product of Dirichlet process location-scale mixtures that enable independent clustering at multiple scales, which result in varying levels of information sharing across samples. First, we develop the approach for independent multivariate data. Subsequently we generalize it to multivariate time-series data under the framework of multi-subject Vector Autoregressive (VAR) models that is our primary focus, which go beyond parametric single-subject VAR models. We establish posterior consistency and develop efficient posterior computation for implementation. Extensive numerical studies involving VAR models show distinct advantages over competing methods, in terms of estimation, clustering, and feature selection accuracy. Our resting state fMRI analysis from the Human Connectome Project reveals biologically interpretable connectivity differences between distinct intelligence groups, while another air pollution application illustrates the superior forecasting accuracy compared to alternate methods.
翻译:基于Drichlet工艺混合物的Bayesian非参数方法在各个领域都取得了巨大成功,在通过具有相同参数的组群样本来借取信息方面,这些方法具有吸引力;然而,在不同的环境中,这些方法可能会遇到障碍,在不同的环境中,物体只能沿着一个轴子集成,或样品组群只分享一个相同参数组群。我们通过开发一种新颖的Drichlet工艺点定位级混合物产品类别来克服这些局限性,这种产品类别能够在不同尺度上进行独立的组合,从而导致不同样本之间的信息分享程度不同。首先,我们为独立的多变量数据制定了方法。随后,我们将其推广到多主题矢量自动递增模型框架下的多变量时间序列数据,这是我们的主要重点,这些模型超越了参数单项单项VAR模型。我们建立了后表一致性,并为执行开发了高效的外表象计算方法。涉及VAR模型的广泛数字研究表明,在估算、组合和特征选择精确度方面,不同的方法具有明显的优势。我们从人类连接项目中进行的状态FMRI分析揭示了不同可解释的连通性联系性差异,而另一个的精确性方法则比较精确性,同时展示了不同的情报组的精确性应用。