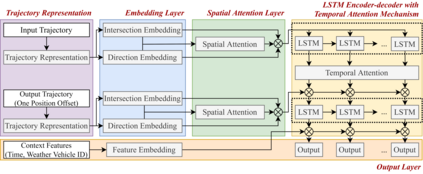
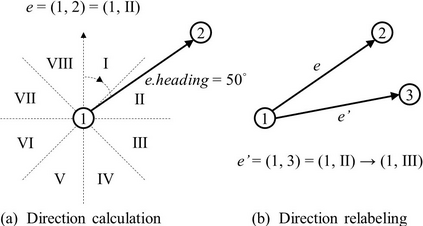
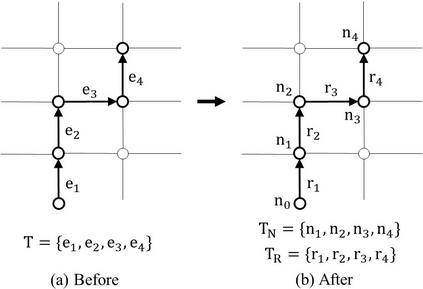
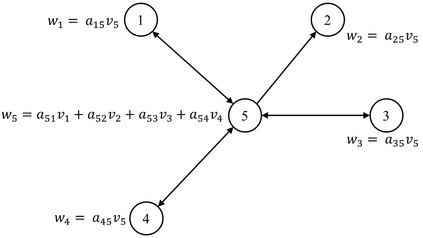
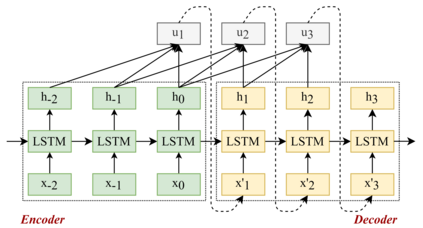
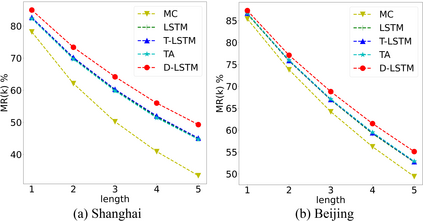
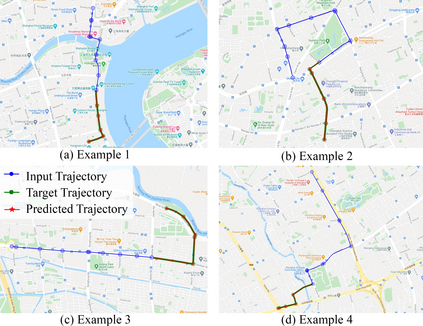
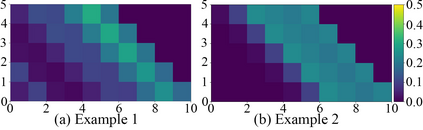
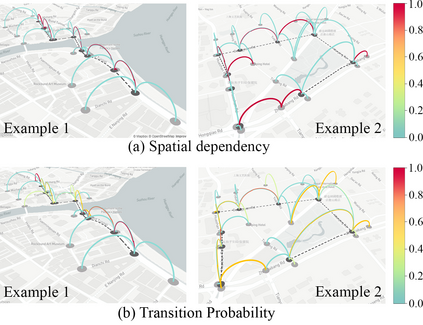
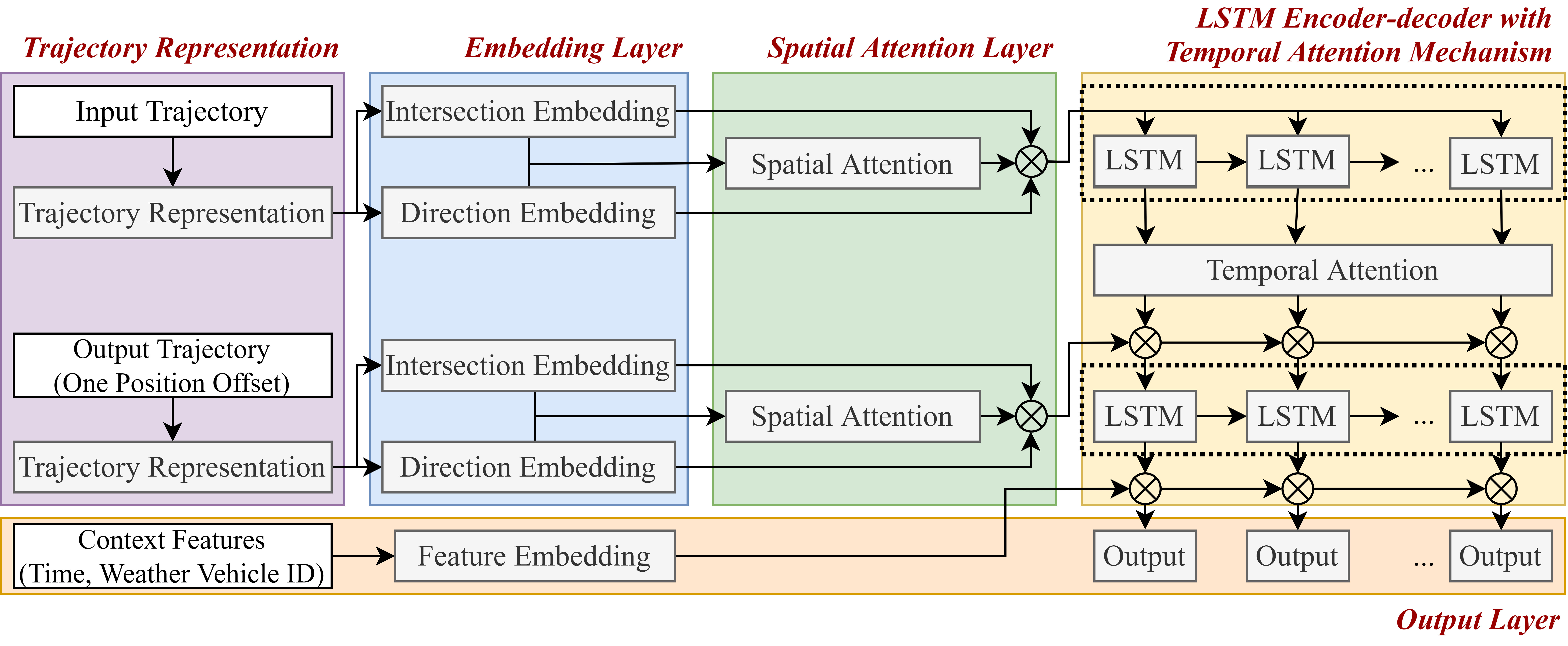
Trajectory prediction of vehicles at the city scale is of great importance to various location-based applications such as vehicle navigation, traffic management, and location-based recommendations. Existing methods typically represent a trajectory as a sequence of grid cells, road segments or intention sets. None of them is ideal, as the cell-based representation ignores the road network structures and the other two are less efficient in analyzing city-scale road networks. In addition, most models focus on predicting the immediate next position, and are difficult to generalize for longer sequences. To address these problems, we propose a novel sequence-to-sequence model named D-LSTM (Direction-based Long Short-Term Memory), which represents each trajectory as a sequence of intersections and associated movement directions, and then feeds them into a LSTM encoder-decoder network for future trajectory generation. Furthermore, we introduce a spatial attention mechanism to capture dynamic spatial dependencies in road networks, and a temporal attention mechanism with a sliding context window to capture both short- and long-term temporal dependencies in trajectory data. Extensive experiments based on two real-world large-scale taxi trajectory datasets show that D-LSTM outperforms the existing state-of-the-art methods for vehicle trajectory prediction, validating the effectiveness of the proposed trajectory representation method and spatiotemporal attention mechanisms.
翻译:城市规模车辆的轨迹预测对于车辆导航、交通管理和基于地点的建议等各种基于地点的应用非常重要。现有方法通常代表电网细胞序列、路段或意图组合的轨迹。其中没有一个是理想的,因为基于细胞的代表忽略了公路网络结构,而另外两个在分析城市规模的道路网络方面效率较低。此外,大多数模型侧重于预测近期下一位置,难以概括较长的顺序。为了解决这些问题,我们提议了一个名为D-LSTM(基于定位的长期短期记忆)的新式顺序对顺序模型,它代表每个轨迹,作为交叉路段和相关移动方向的序列,然后将其输入一个LSTM编码脱coder网络,用于未来轨迹生成。此外,我们引入一个空间关注机制,以捕捉公路网络中动态空间依赖性,以及一个时间关注机制,以滑动背景窗口捕捉轨迹数据的短期和长期依赖性时间依赖性。基于两个真实世界范围的大规模轨迹定位模型进行广泛的实验,以模拟汽车轨迹预测方法的现有轨道定位方法显示DSMANSS。