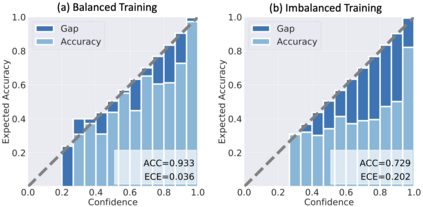
Although deep learning prediction models have been successful in the discrimination of different classes, they can often suffer from poor calibration across challenging domains including healthcare. Moreover, the long-tail distribution poses great challenges in deep learning classification problems including clinical disease prediction. There are approaches proposed recently to calibrate deep prediction in computer vision, but there are no studies found to demonstrate how the representative models work in different challenging contexts. In this paper, we bridge the confidence calibration from computer vision to medical imaging with a comparative study of four high-impact calibration models. Our studies are conducted in different contexts (natural image classification and lung cancer risk estimation) including in balanced vs. imbalanced training sets and in computer vision vs. medical imaging. Our results support key findings: (1) We achieve new conclusions which are not studied under different learning contexts, e.g., combining two calibration models that both mitigate the overconfident prediction can lead to under-confident prediction, and simpler calibration models from the computer vision domain tend to be more generalizable to medical imaging. (2) We highlight the gap between general computer vision tasks and medical imaging prediction, e.g., calibration methods ideal for general computer vision tasks may in fact damage the calibration of medical imaging prediction. (3) We also reinforce previous conclusions in natural image classification settings. We believe that this study has merits to guide readers to choose calibration models and understand gaps between general computer vision and medical imaging domains.
翻译:尽管深层次的学习预测模型在对不同阶层的歧视方面是成功的,但它们往往会因为包括医疗保健在内的不同挑战领域的校准不力而受到影响。此外,长尾分布在深层次学习分类问题,包括临床疾病预测方面提出了巨大挑战。最近提出了一些方法,以校准计算机愿景中的深度预测,但没有发现任何研究来证明具有代表性的模式在不同的挑战背景下如何运作。在本文件中,我们将从计算机愿景到医学成像的信任校准与四个高影响校准模型的比较研究相衔接起来。我们的研究在不同的背景下(自然图像分类和肺癌风险估计)进行,包括平衡与不平衡的培训组合和计算机愿景与医学成像的预测。我们的成果支持了主要结论:(1) 我们达成新结论,但在不同学习背景下没有研究过,例如,我们没有发现将两个校准模型结合起来,既减轻过份的预测,又会导致不自信的预测,而计算机愿景领域的更简单的校准模型往往更普遍地适用于医学成像。(2)我们强调一般计算机愿景任务与医学成像预测之间的差距,例如,为一般计算机愿景的校准方法理想和一般的计算机成像学领域之间的差别,我们还相信,在一般的成像学中可以加强以往的成像学领域之间的差别。