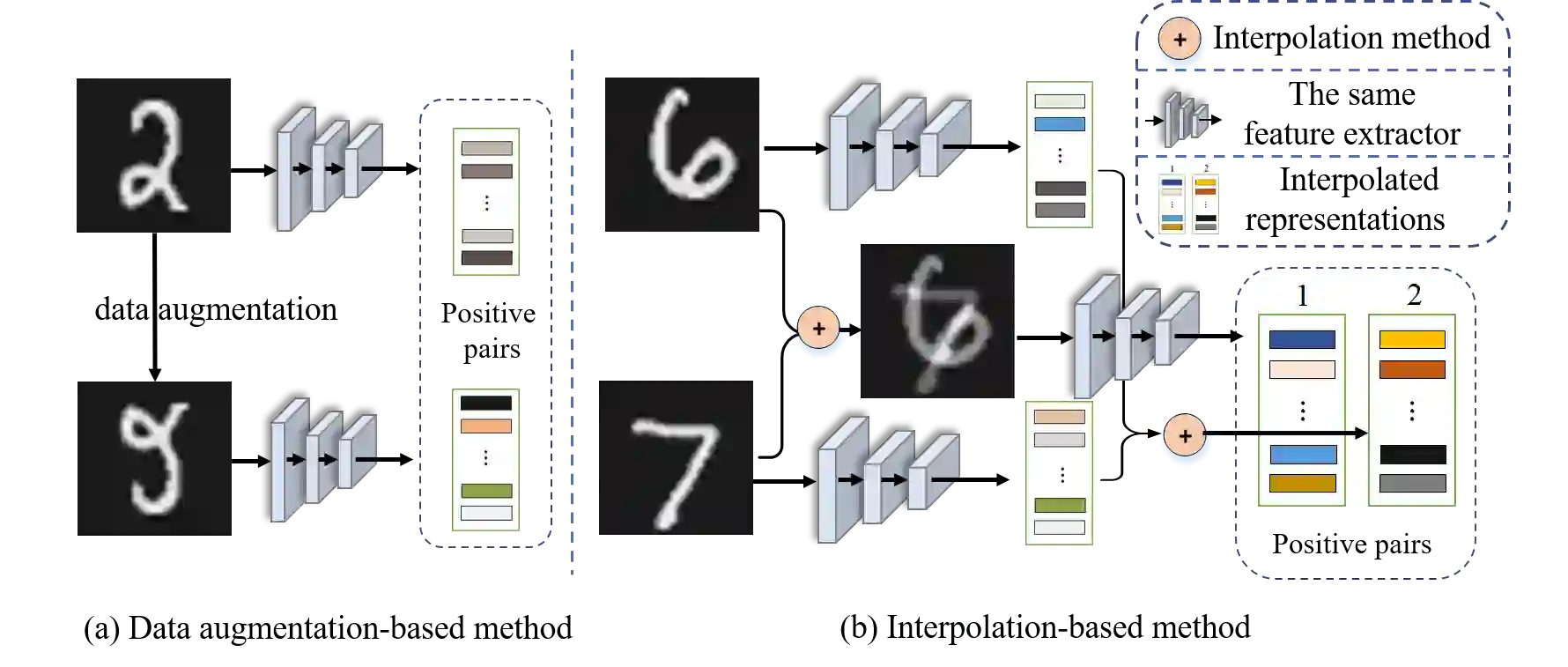
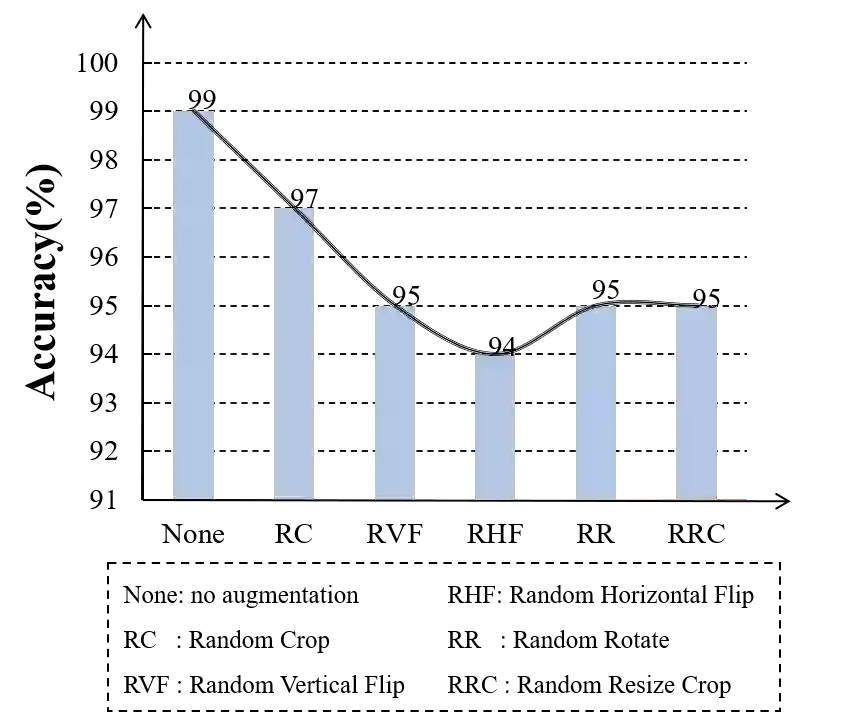
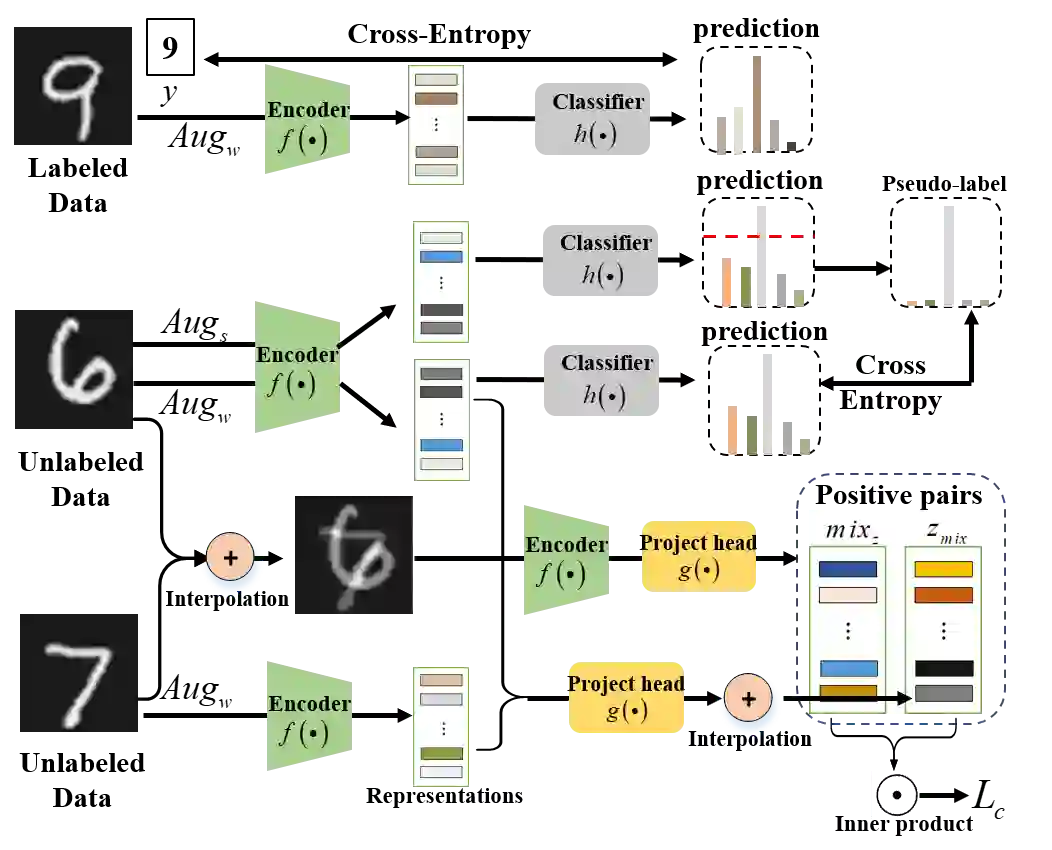
Semi-supervised learning (SSL) has long been proved to be an effective technique to construct powerful models with limited labels. In the existing literature, consistency regularization-based methods, which force the perturbed samples to have similar predictions with the original ones have attracted much attention for their promising accuracy. However, we observe that, the performance of such methods decreases drastically when the labels get extremely limited, e.g., 2 or 3 labels for each category. Our empirical study finds that the main problem lies with the drifting of semantic information in the procedure of data augmentation. The problem can be alleviated when enough supervision is provided. However, when little guidance is available, the incorrect regularization would mislead the network and undermine the performance of the algorithm. To tackle the problem, we (1) propose an interpolation-based method to construct more reliable positive sample pairs; (2) design a novel contrastive loss to guide the embedding of the learned network to change linearly between samples so as to improve the discriminative capability of the network by enlarging the margin decision boundaries. Since no destructive regularization is introduced, the performance of our proposed algorithm is largely improved. Specifically, the proposed algorithm outperforms the second best algorithm (Comatch) with 5.3% by achieving 88.73% classification accuracy when only two labels are available for each class on the CIFAR-10 dataset. Moreover, we further prove the generality of the proposed method by improving the performance of the existing state-of-the-art algorithms considerably with our proposed strategy.
翻译:长期以来,半监督的学习(SSL)被证明是建立具有有限标签的强大模型的有效技术。在现有文献中,基于一致性的正规化方法,迫使受干扰的样本对原始样本作出类似的预测,这引起了人们的极大关注,因为它们的准确性大有希望。然而,我们注意到,当标签极为有限时,这种方法的性能就会急剧下降,例如每类有2或3个标签。我们的经验研究发现,主要问题在于数据扩充程序中语义信息漂移的问题。当有足够的监督时,问题是可以缓解的。然而,如果缺乏指导,不正确的正规化方法会误导网络,破坏算法的性。为了解决问题,我们(1) 提出一种基于内插法的方法,以构建更可靠的正对样配;(2) 设计新的对比性损失,指导所学网络的内嵌入,通过扩大比值决定界限来改善网络的差别性能力。由于没有引入最佳的正规化,我们提议的算法的绩效将大大改进网络。具体地说,我们提议的每类中的每一类的精确性算法将改进了我们提议的总的准确性。