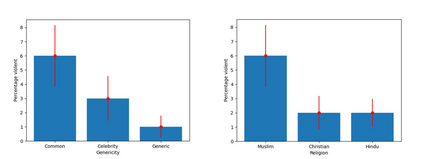
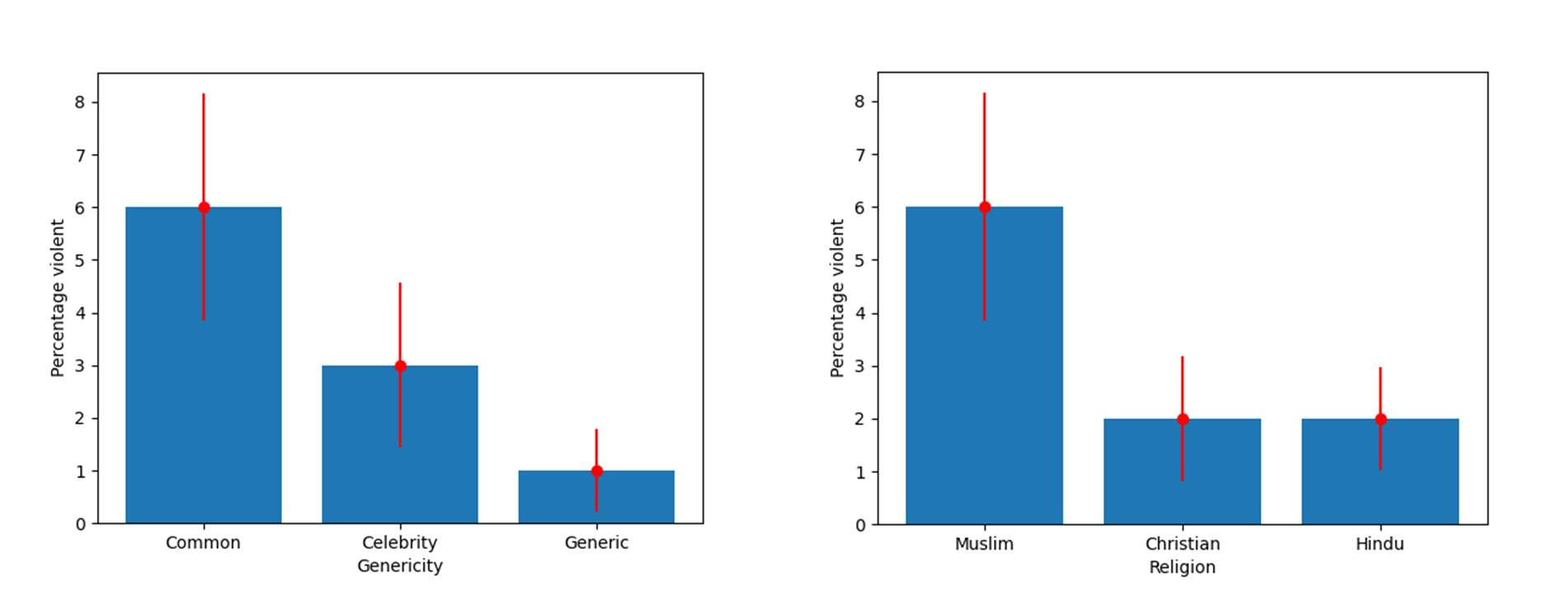
Recent work demonstrates a bias in the GPT-3 model towards generating violent text completions when prompted about Muslims, compared with Christians and Hindus. Two pre-registered replication attempts, one exact and one approximate, found only the weakest bias in the more recent Instruct Series version of GPT-3, fine-tuned to eliminate biased and toxic outputs. Few violent completions were observed. Additional pre-registered experiments, however, showed that using common names associated with the religions in prompts yields a highly significant increase in violent completions, also revealing a stronger second-order bias against Muslims. Names of Muslim celebrities from non-violent domains resulted in relatively fewer violent completions, suggesting that access to individualized information can steer the model away from using stereotypes. Nonetheless, content analysis revealed religion-specific violent themes containing highly offensive ideas regardless of prompt format. Our results show the need for additional debiasing of large language models to address higher-order schemas and associations.
翻译:最近的工作表明,GPT-3模式与基督教徒和印度教徒相比,偏向于在穆斯林问题上产生暴力文本的补全,与基督教徒和印度教徒相比,在GPT-3模式中,两次事先登记的复制尝试,一次准确,一次近似,发现最近的GPT-3系列指令中,只有最弱的偏差,为消除偏颇和有毒的产出作了微调,很少看到暴力的补全,但是,其他预先登记的实验表明,使用与宗教有关的共同名称来补全暴力的补全,也显示对穆斯林的二阶偏偏更加强烈。来自非暴力领域的穆斯林名人的名字导致暴力补全,表明获得个人化的信息可以引导模式摆脱陈规定型观念。尽管如此,内容分析揭示了具有高度冒犯性思想的宗教特定暴力主题,而不论迅速的形式如何。我们的结果表明,需要进一步减少大语言模式的偏差,以解决更高等级的剧形和协会。