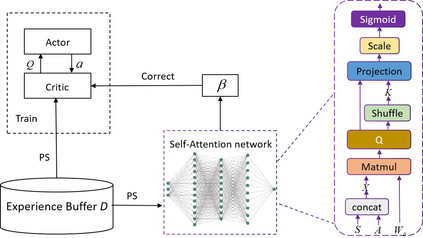
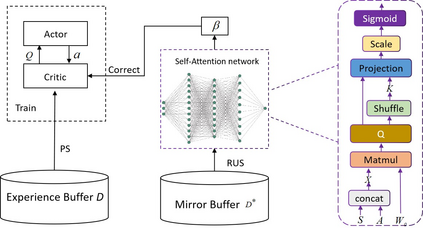
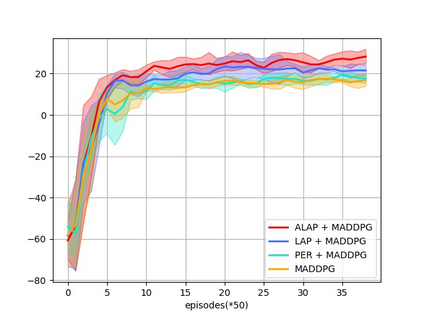
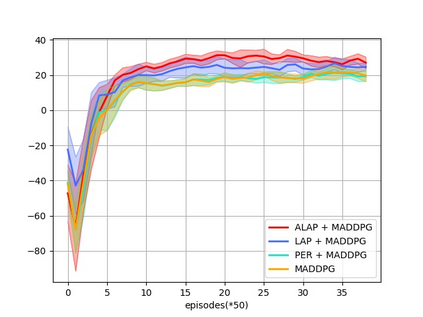
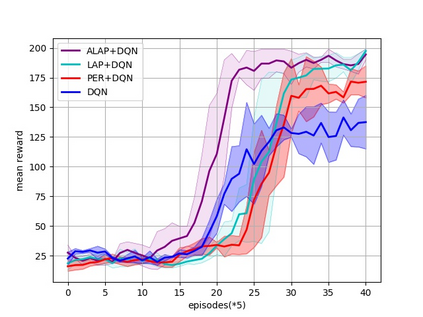
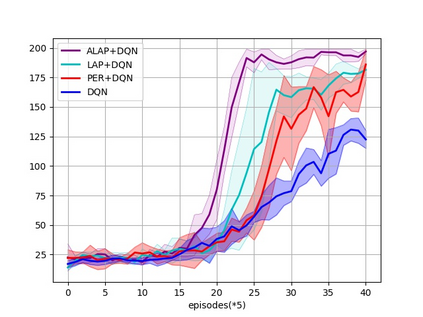
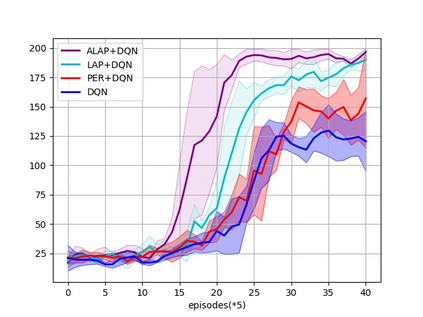
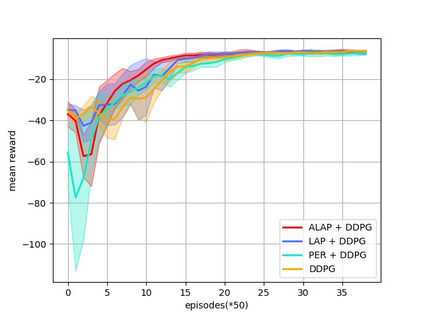
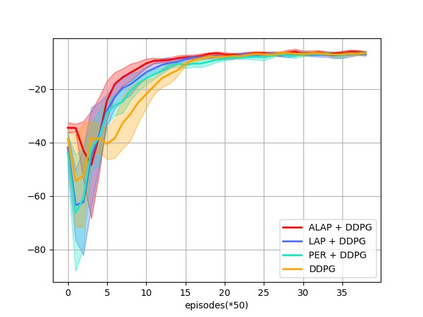
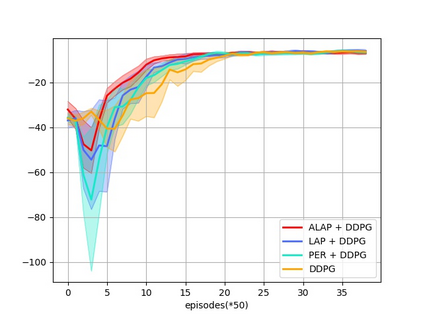
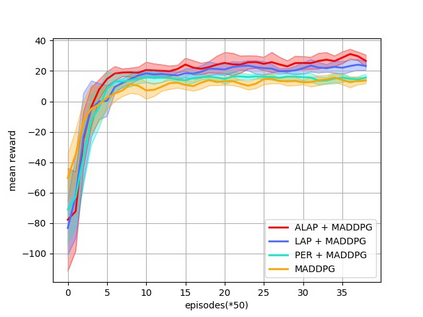
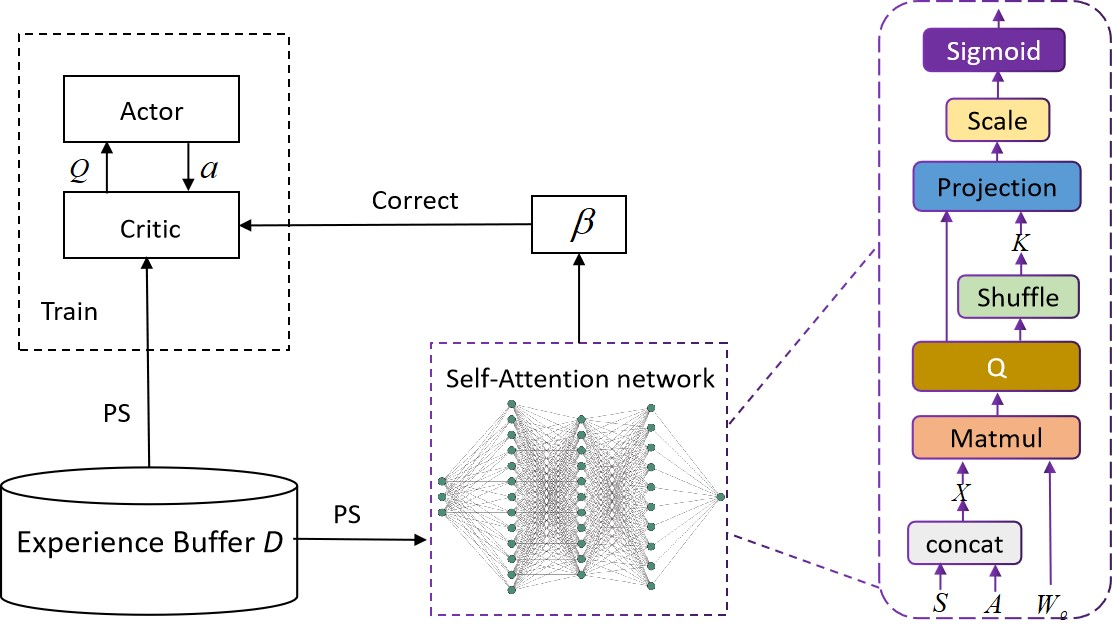
Prioritized Experience Replay (PER) is a technical means of deep reinforcement learning by selecting experience samples with more knowledge quantity to improve the training rate of neural network. However, the non-uniform sampling used in PER inevitably shifts the state-action space distribution and brings the estimation error of Q-value function. In this paper, an Attention Loss Adjusted Prioritized (ALAP) Experience Replay algorithm is proposed, which integrates the improved Self-Attention network with Double-Sampling mechanism to fit the hyperparameter that can regulate the importance sampling weights to eliminate the estimation error caused by PER. In order to verify the effectiveness and generality of the algorithm, the ALAP is tested with value-function based, policy-gradient based and multi-agent reinforcement learning algorithms in OPENAI gym, and comparison studies verify the advantage and efficiency of the proposed training framework.
翻译:暂无翻译