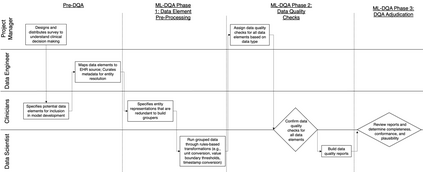
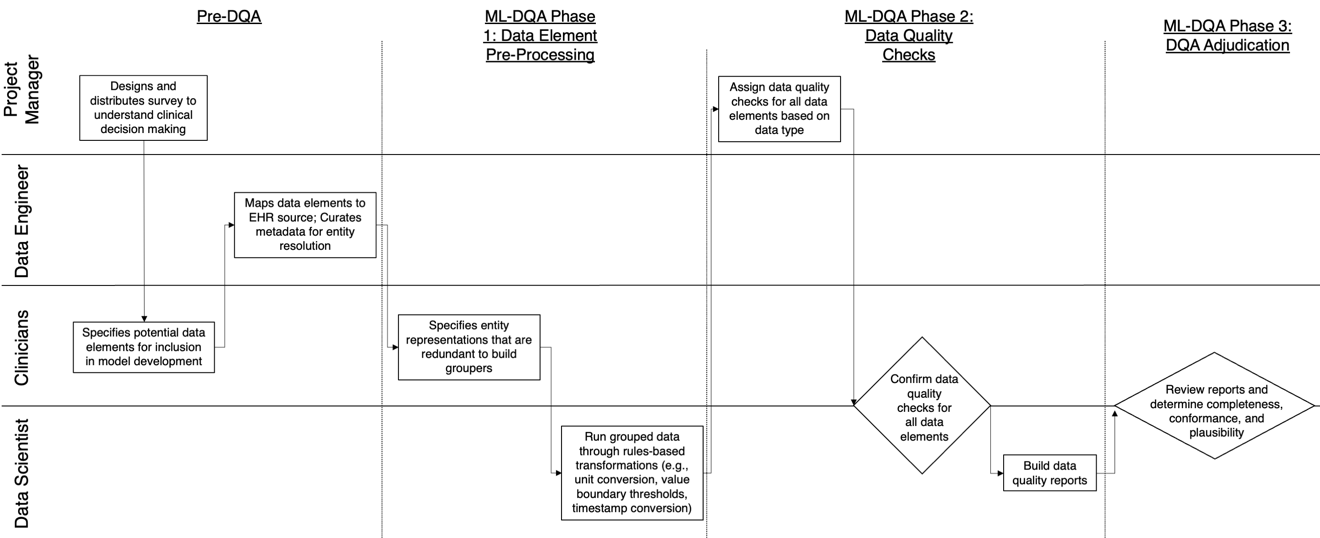
The approaches by which the machine learning and clinical research communities utilize real world data (RWD), including data captured in the electronic health record (EHR), vary dramatically. While clinical researchers cautiously use RWD for clinical investigations, ML for healthcare teams consume public datasets with minimal scrutiny to develop new algorithms. This study bridges this gap by developing and validating ML-DQA, a data quality assurance framework grounded in RWD best practices. The ML-DQA framework is applied to five ML projects across two geographies, different medical conditions, and different cohorts. A total of 2,999 quality checks and 24 quality reports were generated on RWD gathered on 247,536 patients across the five projects. Five generalizable practices emerge: all projects used a similar method to group redundant data element representations; all projects used automated utilities to build diagnosis and medication data elements; all projects used a common library of rules-based transformations; all projects used a unified approach to assign data quality checks to data elements; and all projects used a similar approach to clinical adjudication. An average of 5.8 individuals, including clinicians, data scientists, and trainees, were involved in implementing ML-DQA for each project and an average of 23.4 data elements per project were either transformed or removed in response to ML-DQA. This study demonstrates the importance role of ML-DQA in healthcare projects and provides teams a framework to conduct these essential activities.
翻译:虽然临床研究人员谨慎地使用RWD进行临床调查,但医疗队的ML使用公共数据集,而很少仔细检查以开发新的算法;这项研究缩小了这一差距,开发并验证了以RWD最佳做法为基础的数据质量保证框架ML-DQA; ML-DQA框架适用于两个地理区、不同医疗条件和不同组群的五个ML项目;共为RWD在五个项目中收集了247 536名病人的2 999份质量检查和24份质量报告; 出现了五个一般性做法:所有项目都使用类似方法将冗余数据部分表述成群;所有项目都使用自动化公用事业来建立诊断和药物数据要素;所有项目都使用一个基于规则的变革共同图书馆;所有项目都采用统一的方法对数据要素进行数据质量检查;所有项目都采用类似的临床判断方法;平均5.8人,包括临床医生、数据科学家和受训人员,对RWD进行了质量检查; 每一个ML-D项目在实施MA基本内容时,每个ML-D项目都展示了ML-QA项目的重要性。