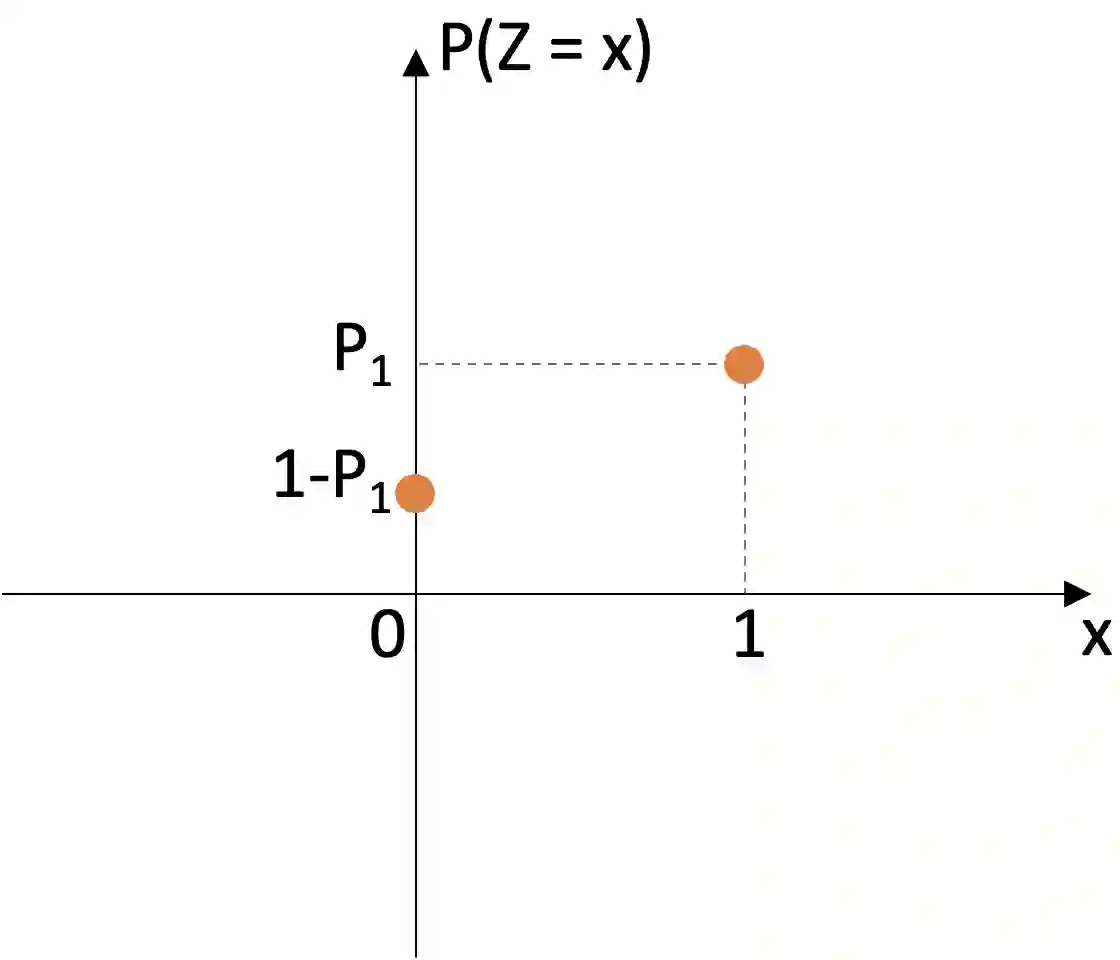
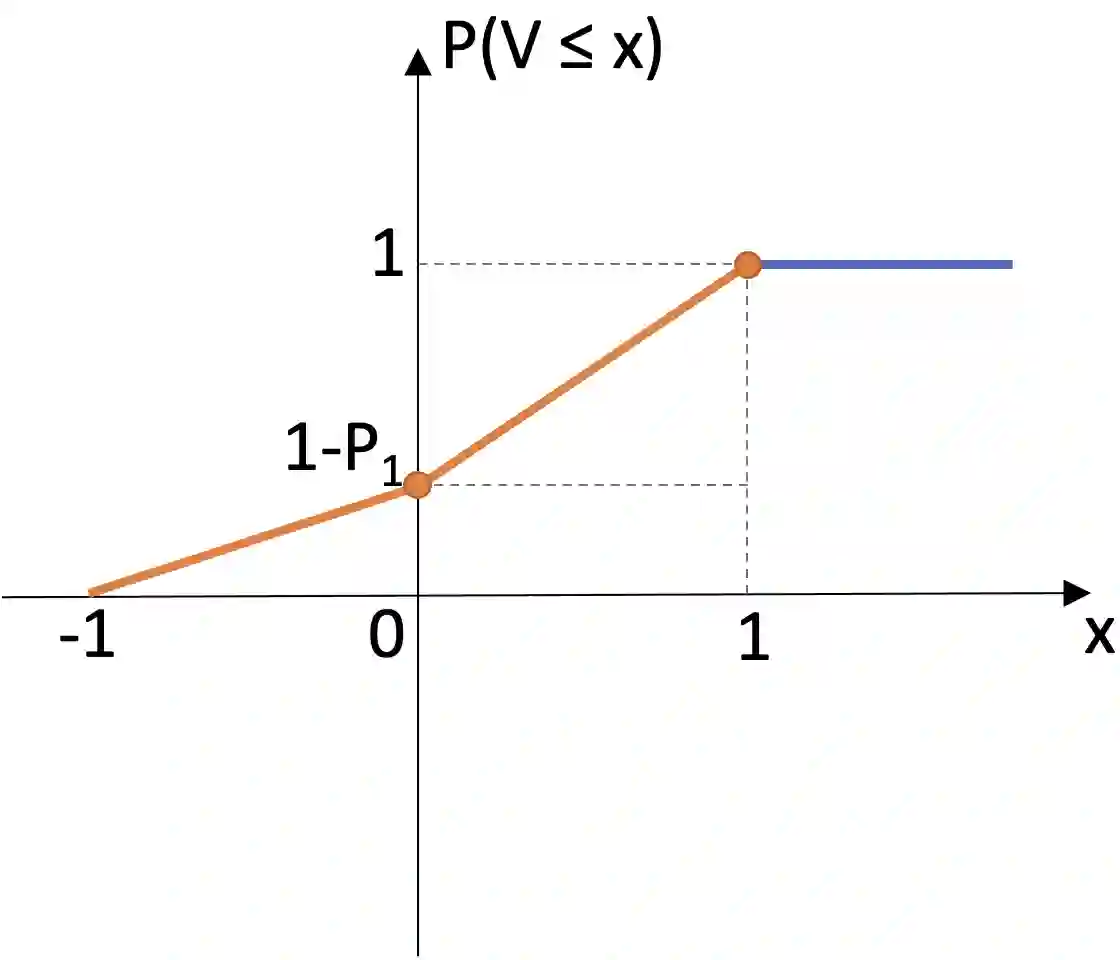
Differential privacy is becoming one gold standard for protecting the privacy of publicly shared data. It has been widely used in social science, data science, public health, information technology, and the U.S. decennial census. Nevertheless, to guarantee differential privacy, existing methods may unavoidably alter the conclusion of the original data analysis, as privatization often changes the sample distribution. This phenomenon is known as the trade-off between privacy protection and statistical accuracy. In this work, we mitigate this trade-off by developing a distribution-invariant privatization (DIP) method to reconcile both high statistical accuracy and strict differential privacy. As a result, any downstream statistical or machine learning task yields essentially the same conclusion as if one used the original data. Numerically, under the same strictness of privacy protection, DIP achieves superior statistical accuracy in a wide range of simulation studies and real-world benchmarks.
翻译:不同隐私正在成为保护公共共享数据隐私的黄金标准,在社会科学、数据科学、公共卫生、信息技术和美国十年一度的人口普查中被广泛使用。然而,为了保障差异隐私,现有方法可能不可避免地改变原始数据分析的结论,因为私有化往往改变抽样分布。这一现象被称为隐私保护与统计准确性之间的权衡。在这项工作中,我们通过制定分配-差异性私有化(DIP)方法来减少这种权衡,以调和高统计准确性和严格的差异性隐私。因此,任何下游统计或机器学习任务都得出与使用原始数据基本相同的结论。在同样严格的隐私保护下,DIP在广泛的模拟研究和现实世界基准中实现了较高的统计准确性。