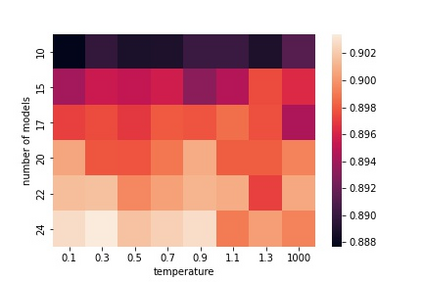
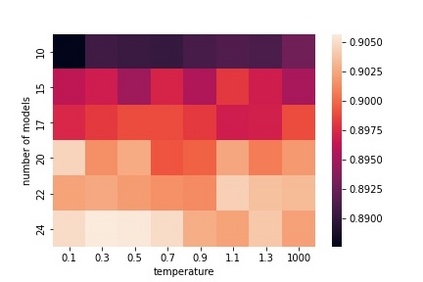
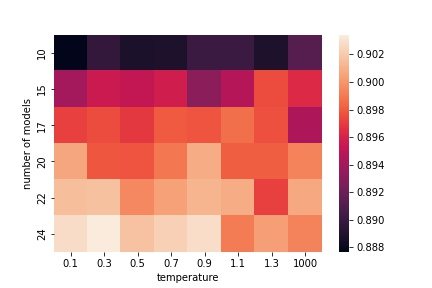
Ensembling is a popular and effective method for improving machine learning (ML) models. It proves its value not only in classical ML but also for deep learning. Ensembles enhance the quality and trustworthiness of ML solutions, and allow uncertainty estimation. However, they come at a price: training ensembles of deep learning models eat a huge amount of computational resources. A snapshot ensembling collects models in the ensemble along a single training path. As it runs training only one time, the computational time is similar to the training of one model. However, the quality of models along the training path is different: typically, later models are better if no overfitting occurs. So, the models are of varying utility. Our method improves snapshot ensembling by selecting and weighting ensemble members along the training path. It relies on training-time likelihoods without looking at validation sample errors that standard stacking methods do. Experimental evidence for Fashion MNIST, CIFAR-10, and CIFAR-100 datasets demonstrates the superior quality of the proposed weighted ensembles c.t. vanilla ensembling of deep learning models.
翻译:集成是改进机器学习(ML)模式的一种普遍而有效的方法,它不仅在古典ML中证明它的价值,而且在深层次学习中也证明它的价值。组合提高ML解决方案的质量和可信赖性,并允许对不确定性进行估计。然而,它们有一个代价:深层次学习模式的培训集合消耗了大量的计算资源。一个快照集集集在单一培训路径的组合中收集模型。由于它只进行一次培训,计算时间与一个模型的培训相似。但是,在培训路径上,模型的质量是不同的:通常情况下,后期模型如果不出现过大,则会更好。因此,这些模型具有不同的用途。我们的方法通过选择和加权共同成员沿培训路径来改进快递集。它依靠培训时间的可能性,而不看标准堆放方法的校准样本错误。Fashion MNIST、CIFAR-10和CIFAR-100数据集的实验性证据显示了拟议加权模型的优劣质。