
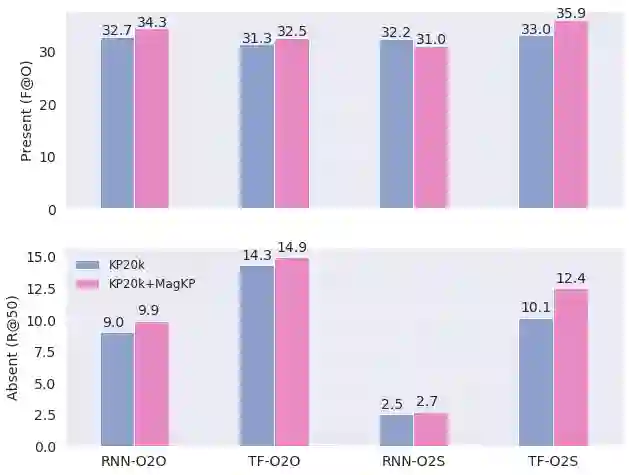
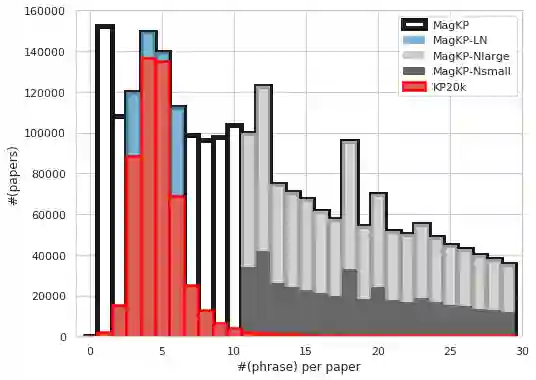
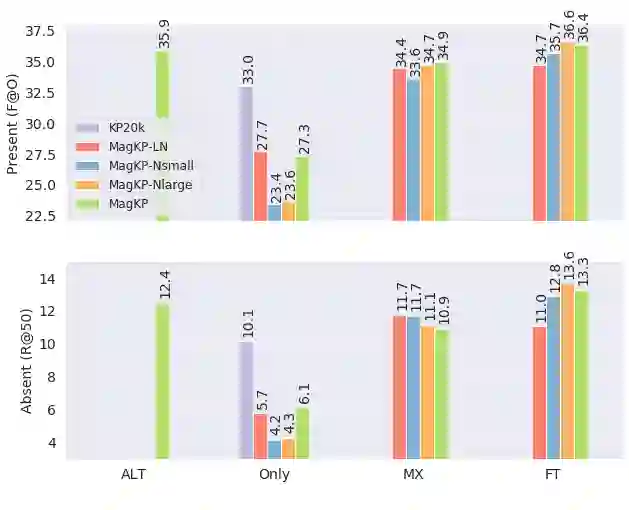
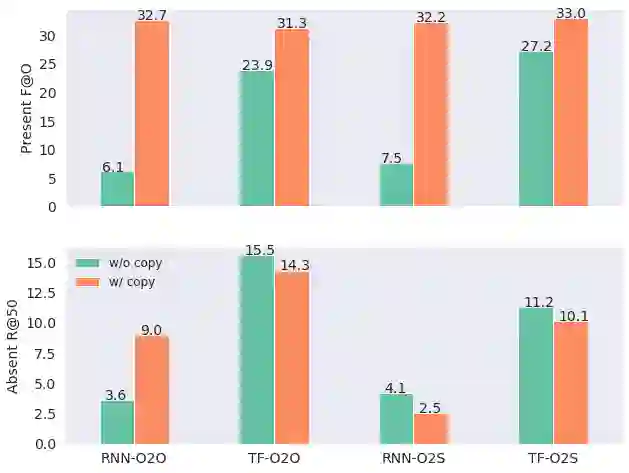
Recent years have seen a flourishing of neural keyphrase generation (KPG) works, including the release of several large-scale datasets and a host of new models to tackle them. Model performance on KPG tasks has increased significantly with evolving deep learning research. However, there lacks a comprehensive comparison among different model designs, and a thorough investigation on related factors that may affect a KPG system's generalization performance. In this empirical study, we aim to fill this gap by providing extensive experimental results and analyzing the most crucial factors impacting the generalizability of KPG models. We hope this study can help clarify some of the uncertainties surrounding the KPG task and facilitate future research on this topic.
翻译:近年来,神经关键词生成(KPG)的作品蓬勃发展,包括发布若干大型数据集和一系列处理这些数据集的新模型;随着深层学习研究的不断演变,KPG任务的示范性业绩显著提高;然而,不同模型设计之间缺乏全面比较,对可能影响KPG系统一般化绩效的相关因素缺乏彻底调查;在这项经验研究中,我们的目标是通过提供广泛的实验结果和分析影响KPG模型通用性的最关键因素来填补这一空白;我们希望这项研究能够有助于澄清围绕KPG任务的一些不确定因素,并便利今后对这一专题的研究。
相关内容

- Today (iOS and OS X): widgets for the Today view of Notification Center
- Share (iOS and OS X): post content to web services or share content with others
- Actions (iOS and OS X): app extensions to view or manipulate inside another app
- Photo Editing (iOS): edit a photo or video in Apple's Photos app with extensions from a third-party apps
- Finder Sync (OS X): remote file storage in the Finder with support for Finder content annotation
- Storage Provider (iOS): an interface between files inside an app and other apps on a user's device
- Custom Keyboard (iOS): system-wide alternative keyboards
Source: iOS 8 Extensions: Apple’s Plan for a Powerful App Ecosystem


