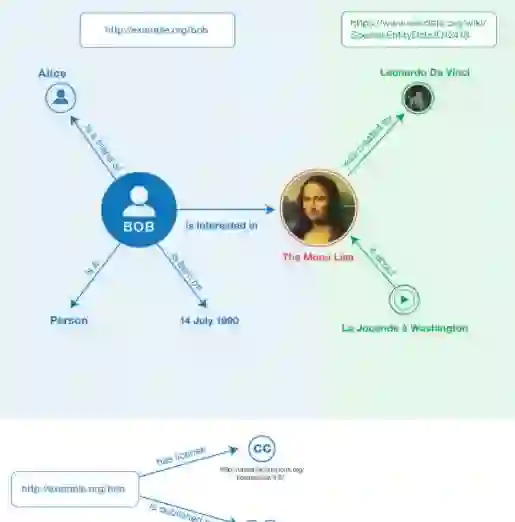
RDF streaming has been explored by the Semantic Web community from many angles, resulting in multiple task formulations and streaming methods. However, for many existing formulations of the problem, reliably benchmarking streaming solutions has been challenging due to the lack of well-described and appropriately diverse benchmark datasets. Existing datasets and evaluations, except a few notable cases, suffer from unclear streaming task scopes, underspecified benchmarks, and errors in the data. To address these issues, we propose RiverBench, an open and collaborative RDF streaming benchmark suite. RiverBench leverages continuous, community-driven processes, established best practices (e.g., FAIR), and built-in quality guarantees. The suite distributes datasets in a common, accessible format, with clear documentation, licensing, and machine-readable metadata. The current release includes a diverse collection of non-synthetic datasets generated by the Semantic Web community, representing many applications of RDF data streaming, all major task formulations, and emerging RDF features (RDF-star). Finally, we present a list of research applications for the suite, demonstrating its versatility and value even beyond the realm of RDF streaming.
翻译:暂无翻译