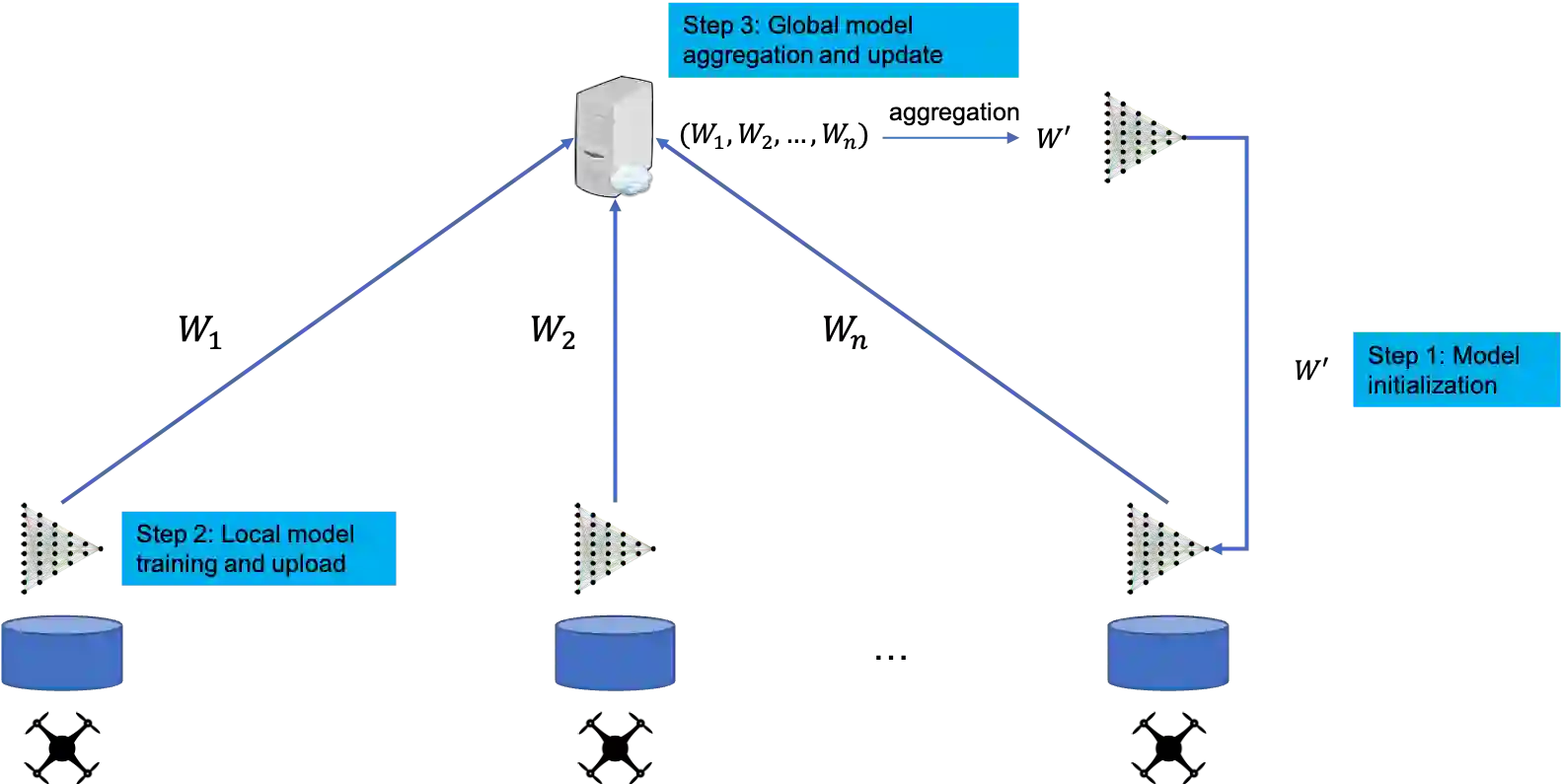
In recent years the applications of machine learning models have increased rapidly, due to the large amount of available data and technological progress.While some domains like web analysis can benefit from this with only minor restrictions, other fields like in medicine with patient data are strongerregulated. In particular \emph{data privacy} plays an important role as recently highlighted by the trustworthy AI initiative of the EU or general privacy regulations in legislation. Another major challenge is, that the required training \emph{data is} often \emph{distributed} in terms of features or samples and unavailable for classicalbatch learning approaches. In 2016 Google came up with a framework, called \emph{Federated Learning} to solve both of these problems. We provide a brief overview on existing Methods and Applications in the field of vertical and horizontal \emph{Federated Learning}, as well as \emph{Fderated Transfer Learning}.
翻译:近年来,由于大量可用数据和技术进展,机器学习模式的应用迅速增加。 虽然网络分析等一些领域仅能通过少量限制而从中受益,但具有患者数据的医学等其他领域监管得更强。特别是,正如欧盟值得信赖的AI倡议或立法中的一般隐私条例最近所强调的那样,机器学习模式的运用发挥了重要作用。另一个重大挑战是,所需要的培训在功能或样本方面常常被分配,无法采用古典学方法。2016年,谷歌制定了一个框架,称为\emph{Federal Learning},以解决这两个问题。我们简要概述了纵向和横向学习领域的现有方法和应用程序,以及iemph{Fedtrategration Learning}。