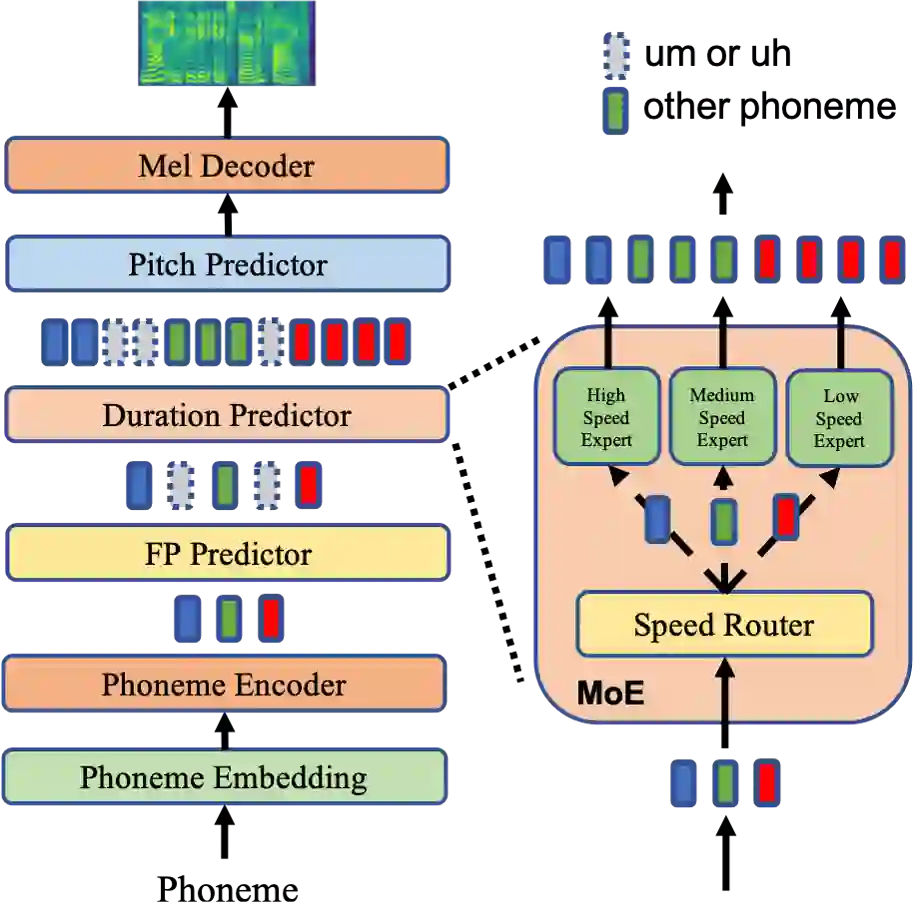
While recent text to speech (TTS) models perform very well in synthesizing reading-style (e.g., audiobook) speech, it is still challenging to synthesize spontaneous-style speech (e.g., podcast or conversation), mainly because of two reasons: 1) the lack of training data for spontaneous speech; 2) the difficulty in modeling the filled pauses (um and uh) and diverse rhythms in spontaneous speech. In this paper, we develop AdaSpeech 3, an adaptive TTS system that fine-tunes a well-trained reading-style TTS model for spontaneous-style speech. Specifically, 1) to insert filled pauses (FP) in the text sequence appropriately, we introduce an FP predictor to the TTS model; 2) to model the varying rhythms, we introduce a duration predictor based on mixture of experts (MoE), which contains three experts responsible for the generation of fast, medium and slow speech respectively, and fine-tune it as well as the pitch predictor for rhythm adaptation; 3) to adapt to other speaker timbre, we fine-tune some parameters in the decoder with few speech data. To address the challenge of lack of training data, we mine a spontaneous speech dataset to support our research this work and facilitate future research on spontaneous TTS. Experiments show that AdaSpeech 3 synthesizes speech with natural FP and rhythms in spontaneous styles, and achieves much better MOS and SMOS scores than previous adaptive TTS systems.
翻译:虽然最近演讲(TTS)模型的文本在综合阅读风格(例如,音频书)的演讲中表现非常出色,但合成自发式演讲(例如,播客或对话)仍具有挑战性,原因有二:(1) 缺乏自发演讲的培训数据;(2) 在自发演讲中,难以模拟填充的暂停(um和uh)和多种节奏。在本文中,我们开发了AdaSpeech 3, 一个适应性TTS系统, 一个经过良好训练的阅读风格 TTTS 模型, 用于自发式演讲。 具体地说,1,在文本序列中适当插入填充的暂停(FP),我们为TTS模型引入一个FP预测或对话;(2) 模拟不同节奏,我们采用以专家混合(MoE)为基础的期限预测,这包括三名专家分别负责生成快速、中、慢调和慢调时的语音,以及精调的语音预测;(3) 适应其他演讲者,我们调整了TBrimbre, 我们在解调调调调调调调调调调调调调的调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调调