【推荐】基于TVM工具链的深度学习编译器 NNVM compiler发布
转自:陈天奇怪
基于TVM工具链的深度学习编译器 NNVM compiler发布,它支持将包括mxnet,pytorch,caffe2, coreml等在内的深度学习模型编译部署到硬件上并提供多级别联合优化。速度更快,部署更加轻量级。 支持包括树莓派,服务器和各种移动式设备和 cuda, opencl, metal, javascript以及其它各种后端。 欢迎对于深度学习, 编译原理,高性能计算,硬件加速有兴趣的同学一起加入dmlc推动领导开源项目社区。
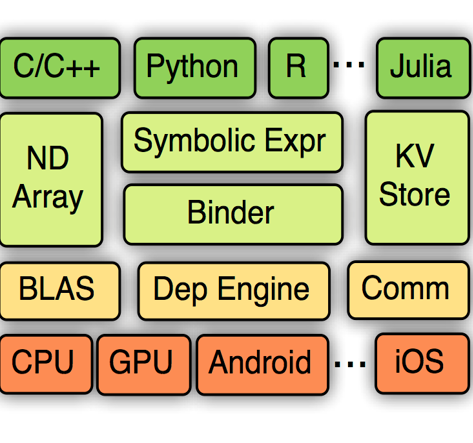
Deep learning has become ubiquitous and indispensable. We are seeing a rising need for deploying deep learning workloads on many kinds of platforms such as mobile phones, GPU, IoT devices and specialized accelerators. Last month, we announced TVM stack to close the gap between deep learning frameworks, and the performance- or efficiency-oriented hardware backends. TVM stack makes it easy to build an end to end compilation for a deep learning framework. However, we think it would even be better to have a unified solution that works for all frameworks.
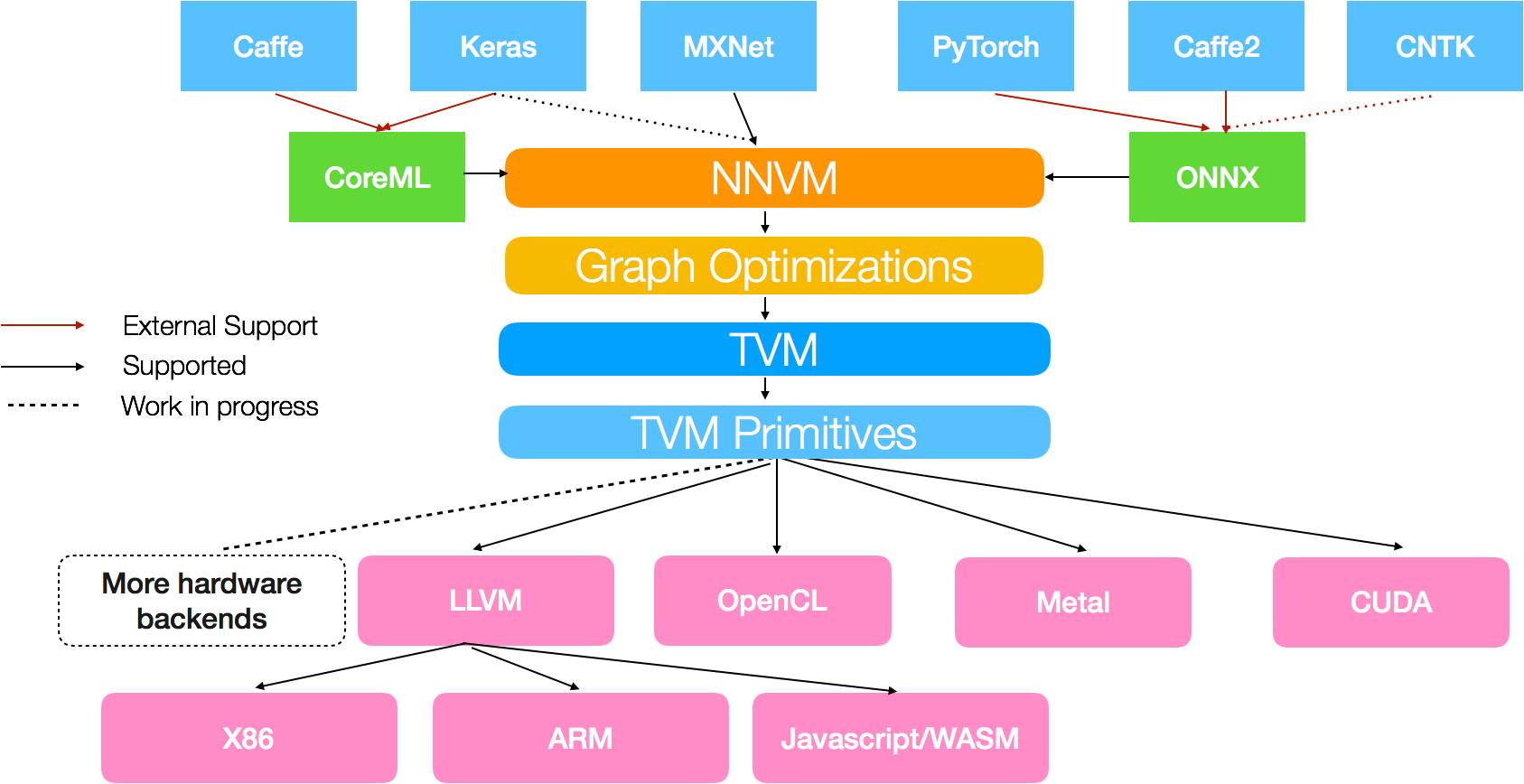
Today, UW Allen school and AWS AI team, together with other contributors, are excited to announce the release of NNVM compiler, an open deep learning compiler to compile front-end framework workloads directly to hardware backends. We build it using the two-level intermediate representation(IR) in the TVM stack. The reader is welcome to refer to the original TVM announcement for more technical details about TVM stack. With the help of TVM stack, NNVM compiler can:
Represent and optimize the common deep learning workloads in high level graph IR
Transform the computation graph to minimize memory utilization, optimize data layout and fuse computation patterns for different hardware backends.
Present an end to end compilation pipeline from front-end deep learning frameworks to bare metal hardwares.
链接:
http://www.tvmlang.org/2017/10/06/nnvm-compiler-announcement.html
原文链接:
https://m.weibo.cn/2397265244/4160107270386180