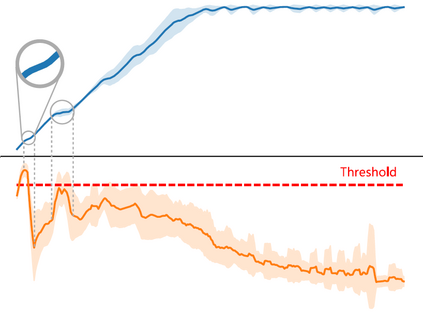
Training deep reinforcement learning (DRL) models usually requires high computation costs. Therefore, compressing DRL models possesses immense potential for training acceleration and model deployment. However, existing methods that generate small models mainly adopt the knowledge distillation based approach by iteratively training a dense network, such that the training process still demands massive computing resources. Indeed, sparse training from scratch in DRL has not been well explored and is particularly challenging due to non-stationarity in bootstrap training. In this work, we propose a novel sparse DRL training framework, "the \textbf{R}igged \textbf{R}einforcement \textbf{L}earning \textbf{L}ottery" (RLx2), which is capable of training a DRL agent \emph{using an ultra-sparse network throughout} for off-policy reinforcement learning. The systematic RLx2 framework contains three key components: gradient-based topology evolution, multi-step Temporal Difference (TD) targets, and dynamic-capacity replay buffer. RLx2 enables efficient topology exploration and robust Q-value estimation simultaneously. We demonstrate state-of-the-art sparse training performance in several continuous control tasks using RLx2, showing $7.5\times$-$20\times$ model compression with less than $3\%$ performance degradation, and up to $20\times$ and $50\times$ FLOPs reduction for training and inference, respectively.
翻译:深加培训学习模式通常需要很高的计算成本。 因此, 压缩 DRL 模型具有巨大的培训加速和模型部署潜力。 但是, 产生小模型的现有方法主要是通过反复培训密集的网络采用基于知识蒸馏法, 这样培训过程仍需要大量的计算资源。 事实上, DRL 中从零到零的训练没有很好地探索, 并且由于靴子区训练中的非静态性, 特别具有挑战性。 在这项工作中, 我们提议了一个新颖的稀疏DRL 培训框架, “\ textbf{R}在培训加速和模型部署方面有巨大的潜力。 RLx2 使得能够高效的上层勘探\ textb{L}罗泰尔能够同时培训一个DRL 代理\ emph{在超薄网络学习。 系统化的 RLx2 框架包含三个关键组成部分: 梯度表层进进进进进进化、 多步调度差异(TD) 和动态功能回放缓冲 。 RLx2 能够高效的上层勘探和不断递减速性( ) ) 展示一些Sload- trest- trade- trueal- true- train- train- trade- trisal- trisal- trisal- trisal ex) imal imal ex ex ex ex ex ex imalisal ex ex 。