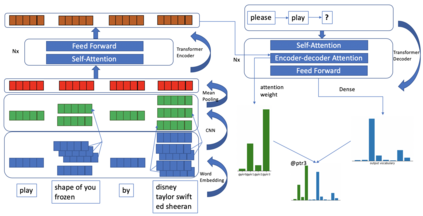
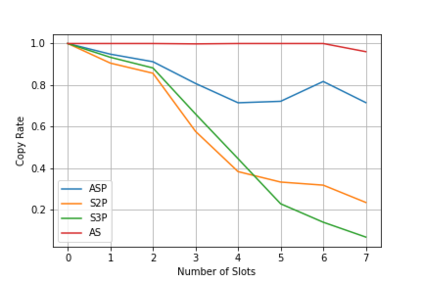
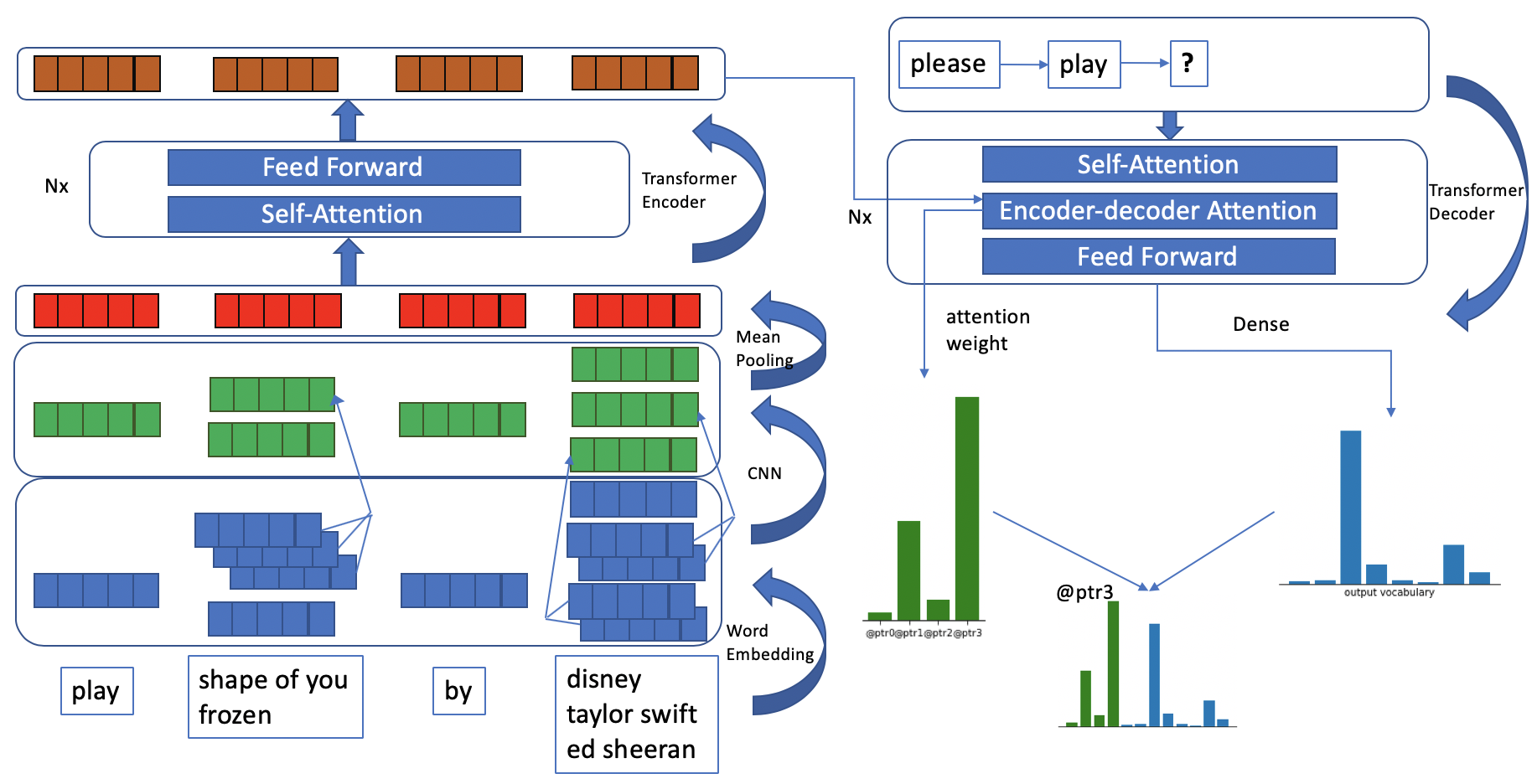
We present a neural model for paraphrasing and train it to generate delexicalized sentences. We achieve this by creating training data in which each input is paired with a number of reference paraphrases. These sets of reference paraphrases represent a weak type of semantic equivalence based on annotated slots and intents. To understand semantics from different types of slots, other than anonymizing slots, we apply convolutional neural networks (CNN) prior to pooling on slot values and use pointers to locate slots in the output. We show empirically that the generated paraphrases are of high quality, leading to an additional 1.29% exact match on live utterances. We also show that natural language understanding (NLU) tasks, such as intent classification and named entity recognition, can benefit from data augmentation using automatically generated paraphrases.
翻译:我们为抛光提供了一个神经模型,并对其进行培训,以生成不灵活的句子。我们通过创建培训数据实现这一点,其中每个输入都配有一些参考副句。这些参考副句子代表了基于附加说明的空格和意图的一种较弱的语义等同类型。为了理解除匿名空格以外的不同种类空格的语义,我们在集合空格值和使用指针定位输出空格之前,先使用共变神经网络。我们从经验中表明,生成的副句子质量很高,导致在现场语句上增加1.29%的精确匹配。我们还表明,自然语言理解任务,如意向分类和名称实体识别,可以通过自动生成的副句子,从数据增强中受益。