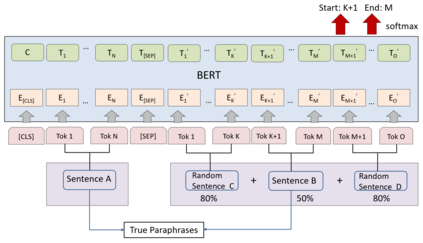
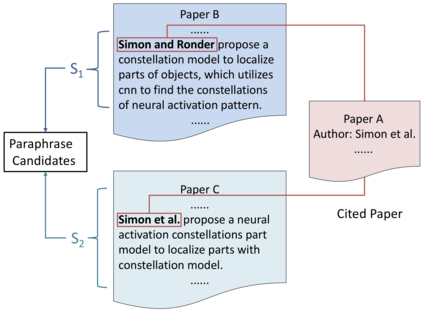
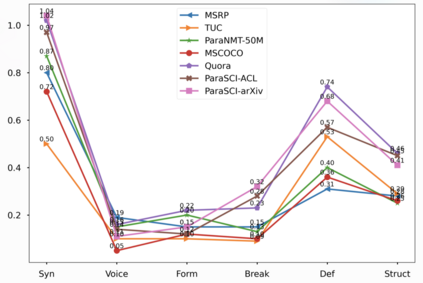
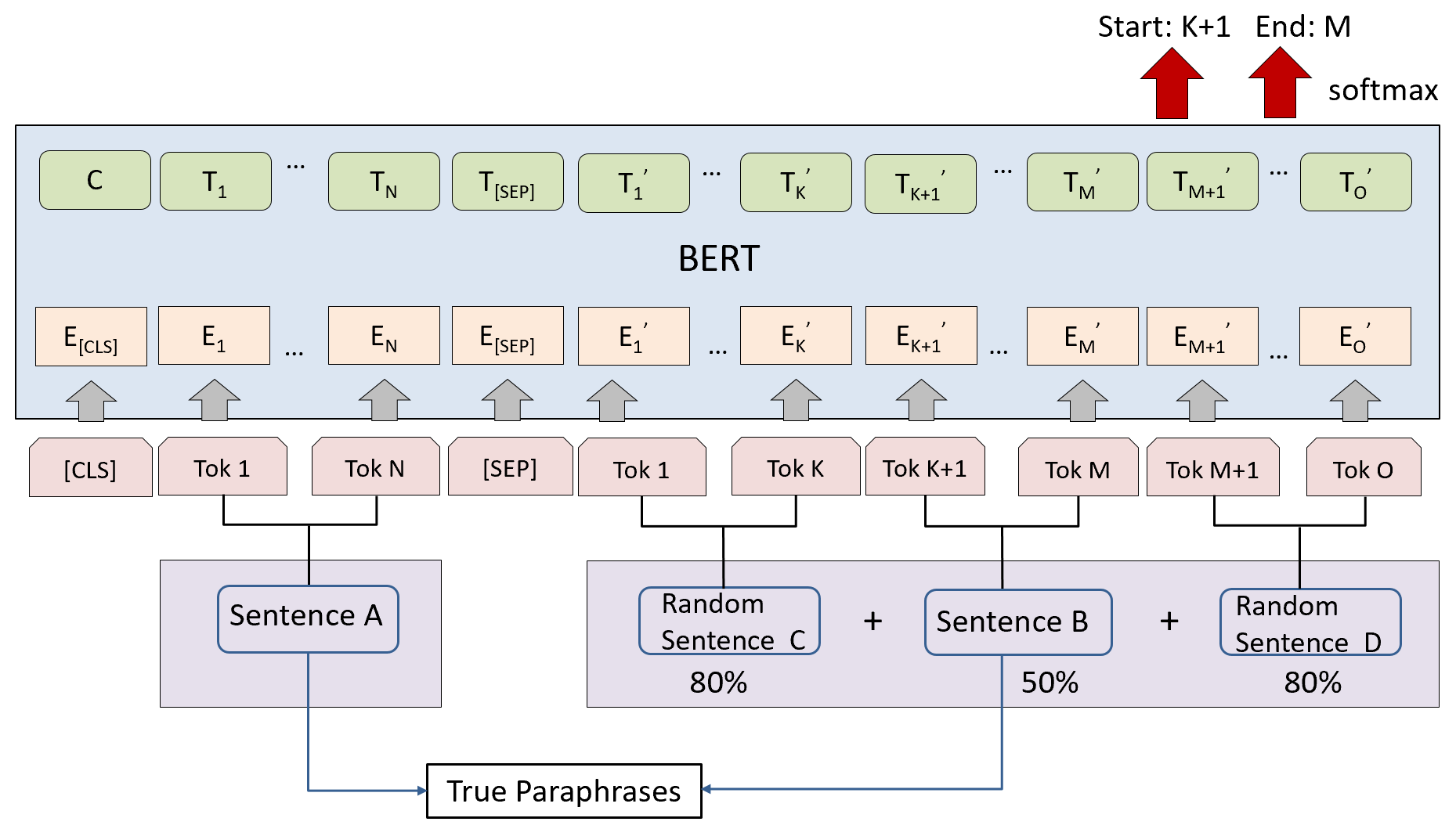
We propose ParaSCI, the first large-scale paraphrase dataset in the scientific field, including 33,981 paraphrase pairs from ACL (ParaSCI-ACL) and 316,063 pairs from arXiv (ParaSCI-arXiv). Digging into characteristics and common patterns of scientific papers, we construct this dataset though intra-paper and inter-paper methods, such as collecting citations to the same paper or aggregating definitions by scientific terms. To take advantage of sentences paraphrased partially, we put up PDBERT as a general paraphrase discovering method. The major advantages of paraphrases in ParaSCI lie in the prominent length and textual diversity, which is complementary to existing paraphrase datasets. ParaSCI obtains satisfactory results on human evaluation and downstream tasks, especially long paraphrase generation.
翻译:我们提出ParaSCI,这是科学领域第一个大规模参数数据集,包括ACL(ParaSCI-ACL)的33,981个参数对和arXiv(ParaSCI-arXiv)的316,063对参数对。我们挖掘科学论文的特征和共同模式,通过纸面内部和纸面间方法构建这一数据集,如收集同一份文件的引文或以科学术语汇总定义。为了利用部分引用的句子,我们提出PDBERT,作为一般参数识别方法。PARSCI中的参数的主要优点在于显著的长度和文字多样性,这是对现有参数数据集的补充。ParaSCI在人类评估和下游任务,特别是长句子生成方面取得了令人满意的结果。