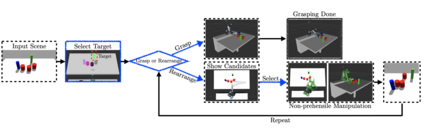
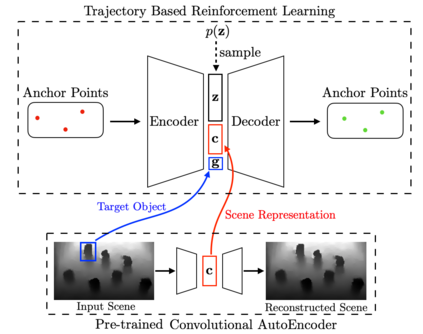
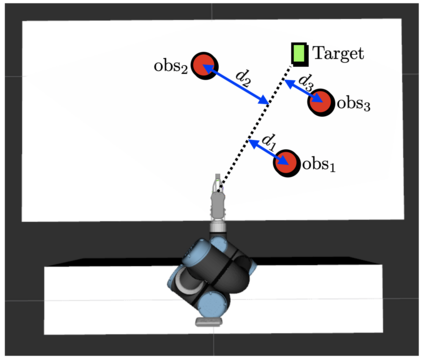
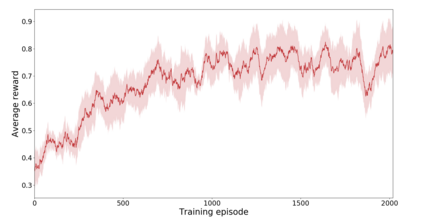
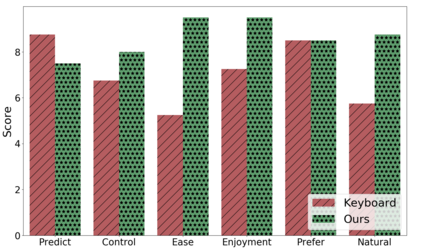
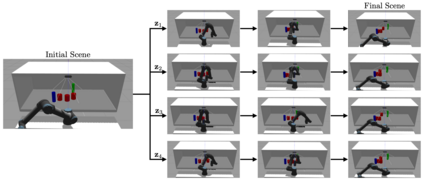
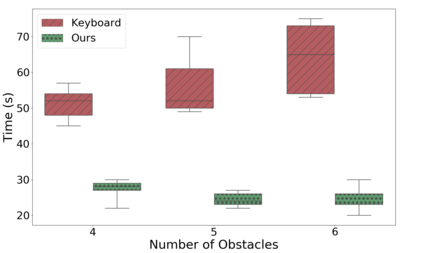
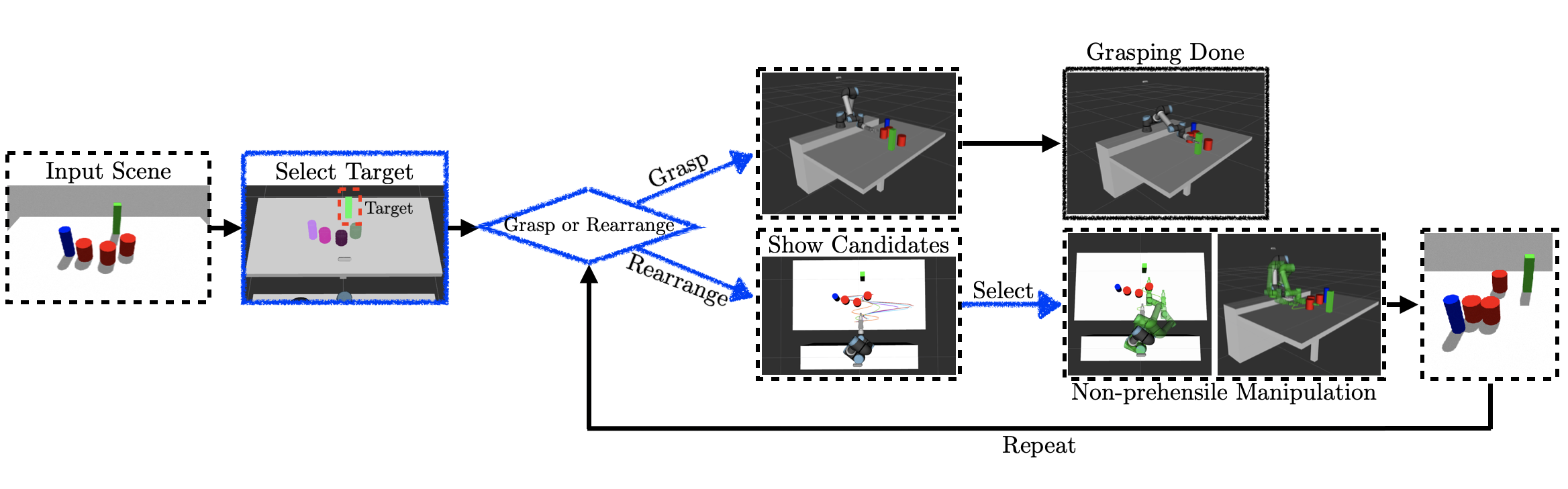
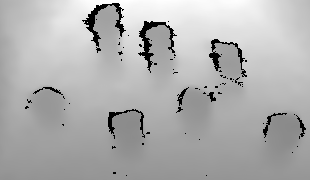In this paper, we present a semi-autonomous teleoperation framework for a pick-and-place task using an RGB-D sensor. In particular, we assume that the target object is located in a cluttered environment where both prehensile grasping and non-prehensile manipulation are combined for efficient teleoperation. A trajectory-based reinforcement learning is utilized for learning the non-prehensile manipulation to rearrange the objects for enabling direct grasping. From the depth image of the cluttered environment and the location of the goal object, the learned policy can provide multiple options of non-prehensile manipulation to the human operator. We carefully design a reward function for the rearranging task where the policy is trained in a simulational environment. Then, the trained policy is transferred to a real-world and evaluated in a number of real-world experiments with the varying number of objects where we show that the proposed method outperforms manual keyboard control in terms of the time duration for the grasping.
翻译:在本文中,我们提出了一个使用 RGB-D 传感器进行选取和定位任务的半自主远程操作框架。 特别是, 我们假设目标对象位于一个杂乱的环境中, 为了高效的远程操作, 将先发制人抓住和非先发制人操纵结合起来。 我们利用基于轨迹的强化学习来学习非先发制人操纵来重新排列对象, 以便能够直接抓取。 从杂乱的环境的深度图像和目标对象的位置来看, 所学的政策可以为人类操作者提供多种非先发制人操纵的选项。 我们仔细设计了一种奖赏功能, 用于在模拟环境中对政策进行培训的后期任务。 然后, 将经过培训的政策转移到现实世界, 并在一系列现实世界实验中评估了不同数量的天体, 我们在此实验中显示, 所拟议的方法在捕捉的时间长度上超过了手动键盘控制 。