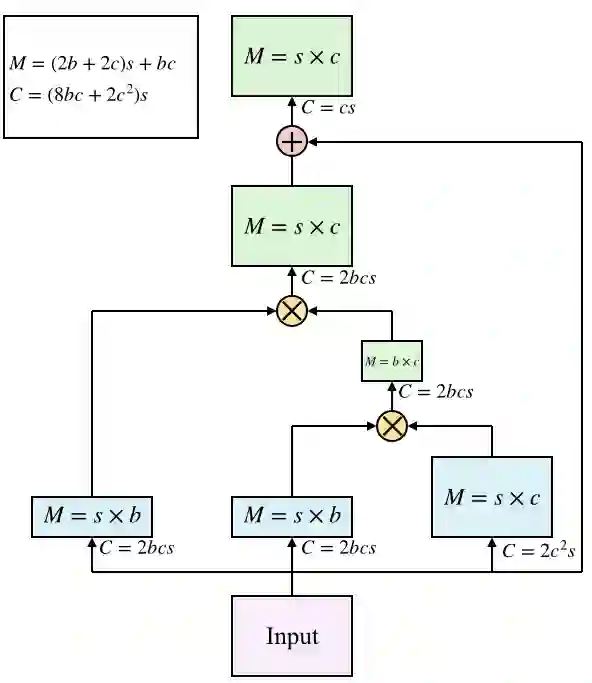
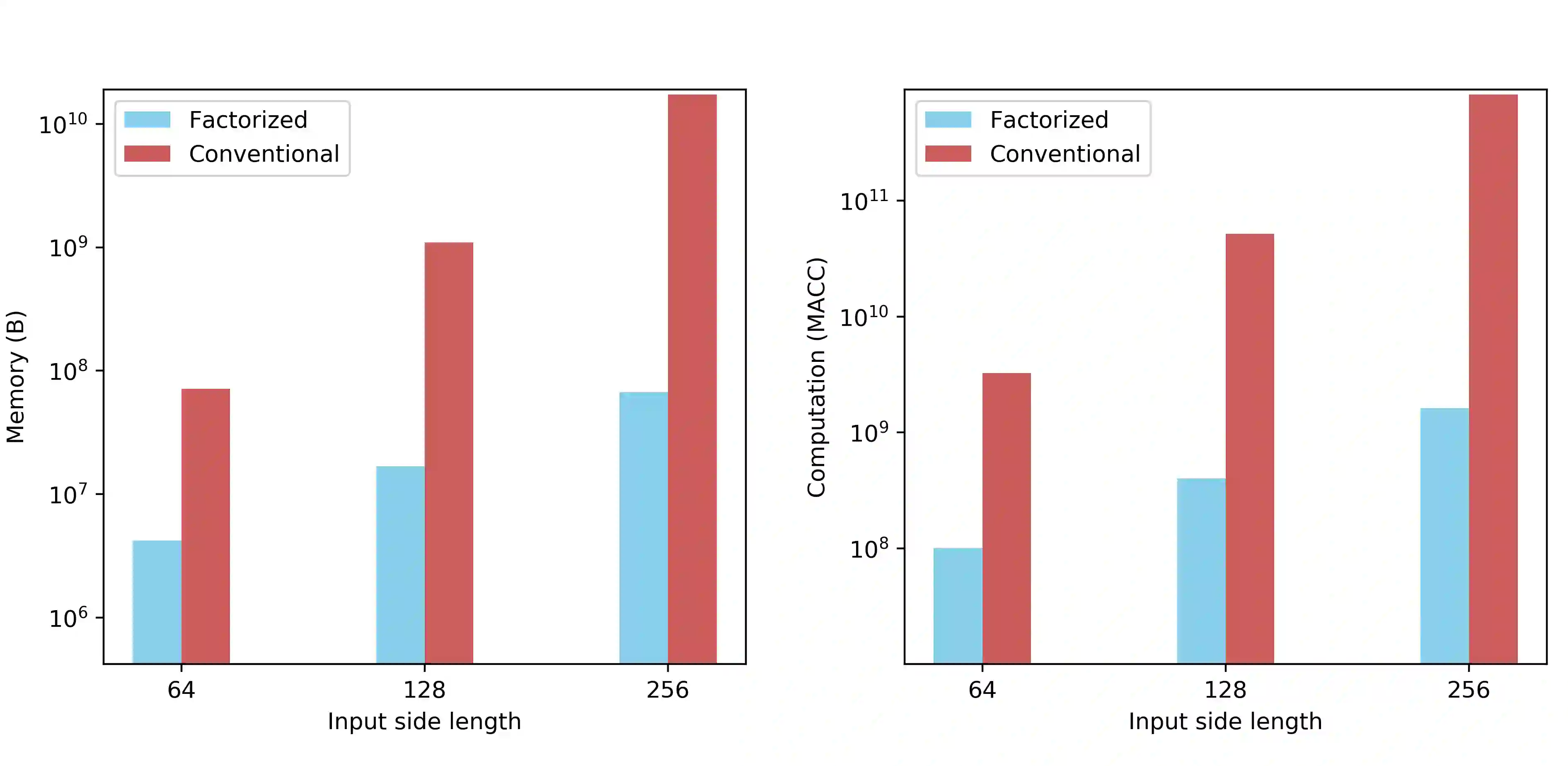
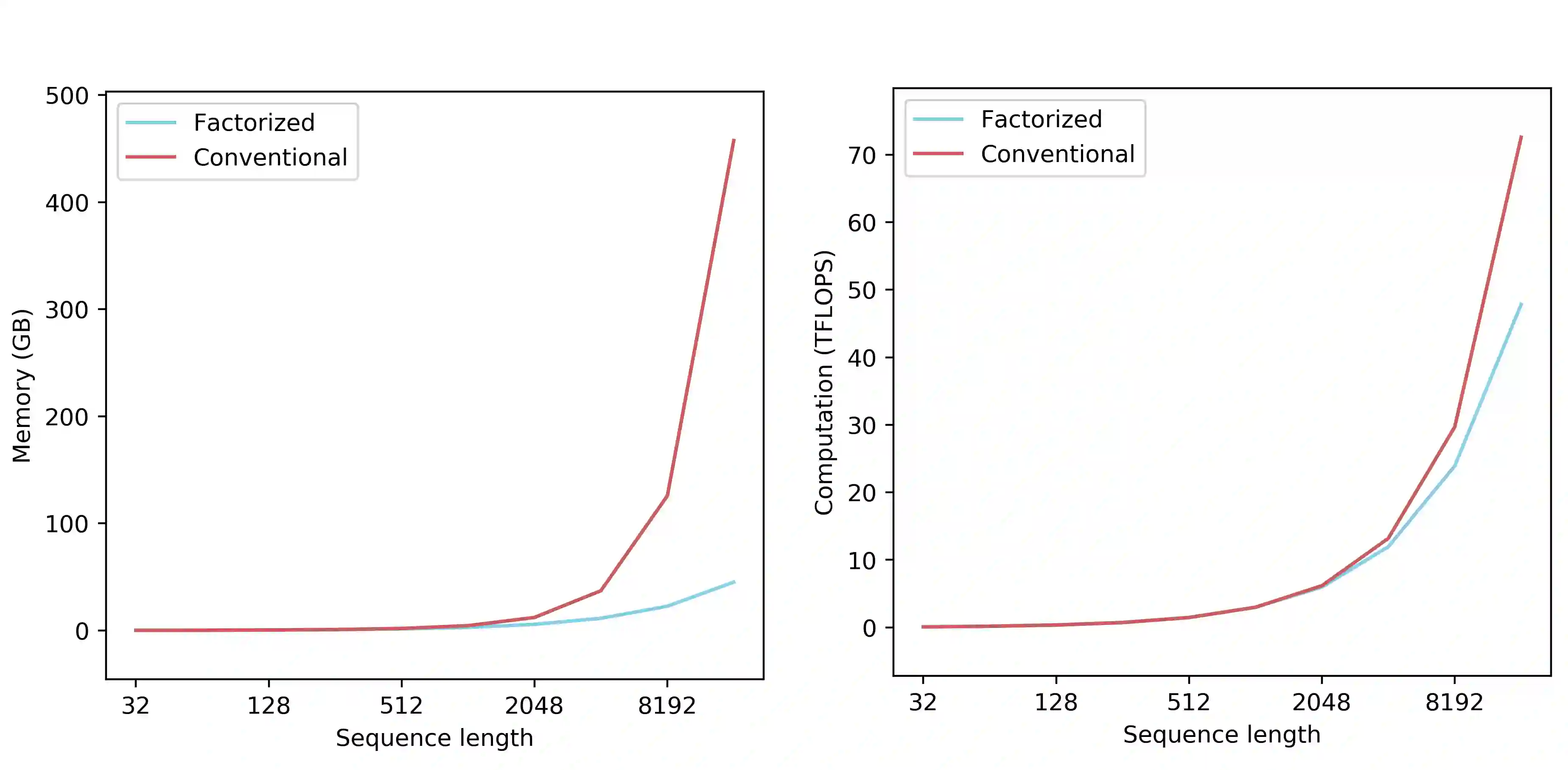
Recent works have been applying self-attention to various fields in computer vision and natural language processing. However, the memory and computational demands of existing self-attention operations grow quadratically with the spatiotemporal size of the input. This prohibits the application of self-attention on large inputs, e.g., long sequences, high-definition images, or large videos. To remedy this, this paper proposes a novel factorized attention (FA) module, which achieves the same expressive power as previous approaches with substantially less memory and computational consumption. The resource-efficiency allows more widespread and flexible application of it. Empirical evaluations on object recognition demonstrate the effectiveness of these advantages. FA-augmented models achieved state-of-the-art performance for object detection and instance segmentation on MS-COCO. Further, the resource-efficiency of FA democratizes self-attention to fields where the prohibitively high costs currently prevent its application. The state-of-the-art result for stereo depth estimation on the Scene Flow dataset exemplifies this.
翻译:最近的著作对计算机视觉和自然语言处理的各个领域应用了自我关注。然而,现有自我关注行动的记忆和计算要求随着输入的片段尺寸而增长四倍。这禁止对大型投入,例如长序列、高清晰图像或大型视频应用自我关注。为了纠正这一点,本文件建议采用一种新的分系数关注模块,该模块与以往的做法具有相同的表达力,但记忆和计算消耗要少得多。资源效率允许更广泛地和灵活地应用该模块。关于目标识别的经验性评估证明了这些优势的有效性。FA强化模型实现了在MS-CO上进行天体探测和实例分解的先进性能。此外,FAFA将资源效率民主化为目前无法应用高得令人望重的成本的字段提供自我关注。Scene Flow数据集的立体深度估计结果就说明了这一点。