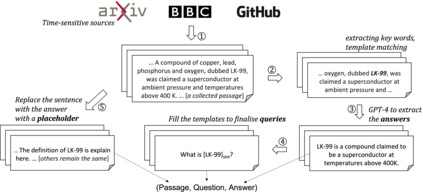
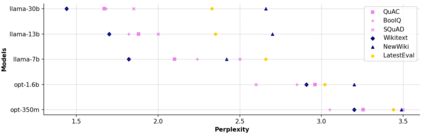
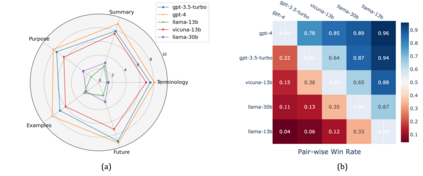
Data contamination in evaluation is getting increasingly prevalent with the emerge of language models pre-trained on super large, automatically-crawled corpora. This problem leads to significant challenges in accurate assessment of model capabilities and generalisations. In this paper, we propose LatestEval, an automatic method leverages the most recent texts to create uncontaminated reading comprehension evaluations. LatestEval avoids data contamination by only using texts published within a recent time window, ensuring no overlap with the training corpora of pre-trained language models. We develop LatestEval automated pipeline to 1) gather latest texts; 2) identify key information, and 3) construct questions targeting the information while removing the existing answers from the context. This encourages models to infer the answers themselves based on the remaining context, rather than just copy-paste. Our experiments demonstrate that language models exhibit negligible memorisation behaviours on LatestEval as opposed to previous benchmarks, suggesting a significantly reduced risk of data contamination and leading to a more robust evaluation. Data and code are publicly available at: https://github.com/liyucheng09/LatestEval.
翻译:暂无翻译