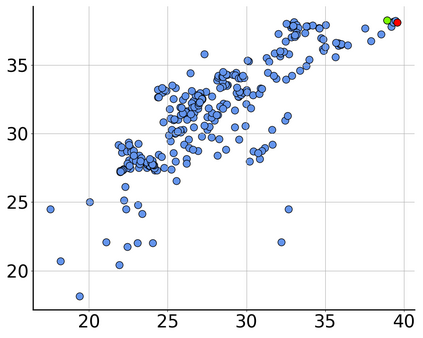
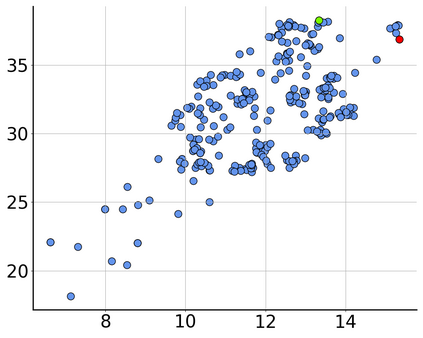
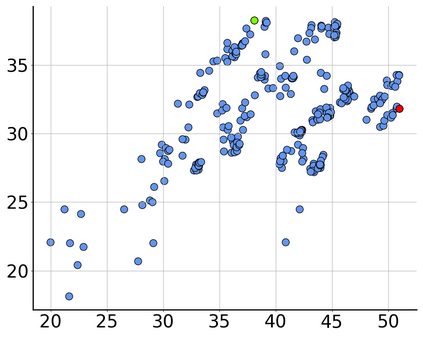
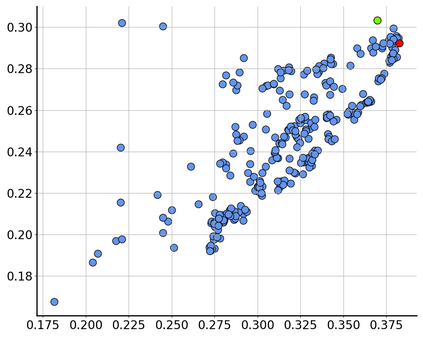
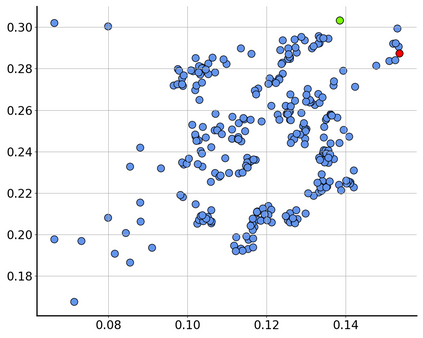
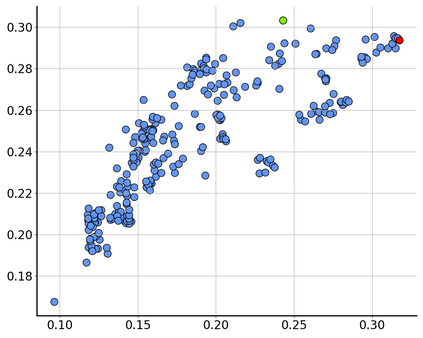
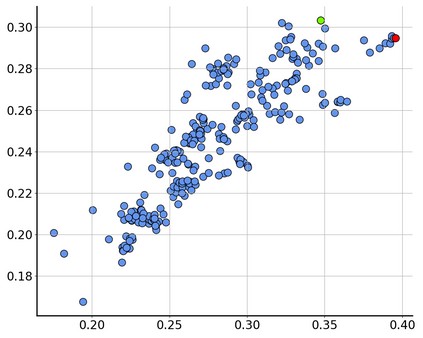
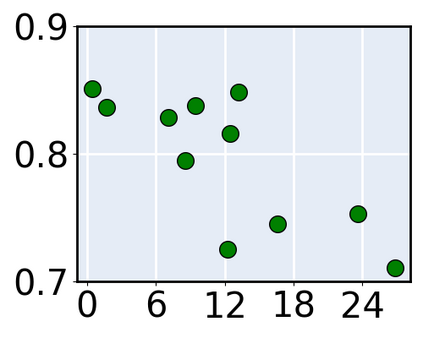
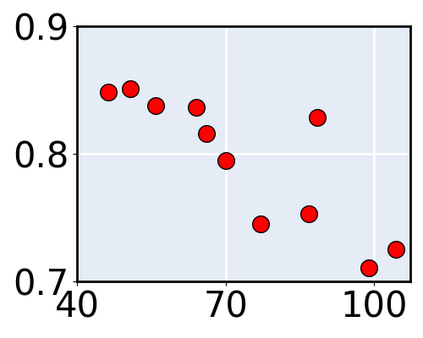
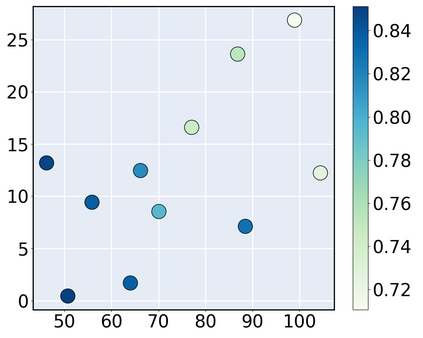
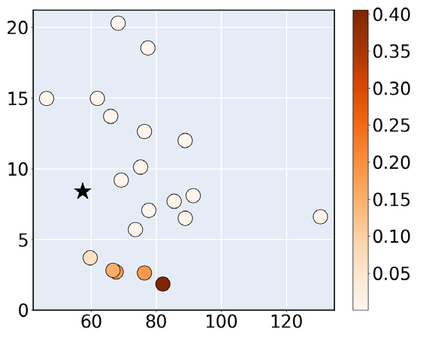
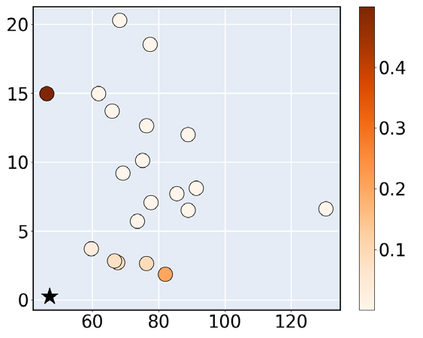
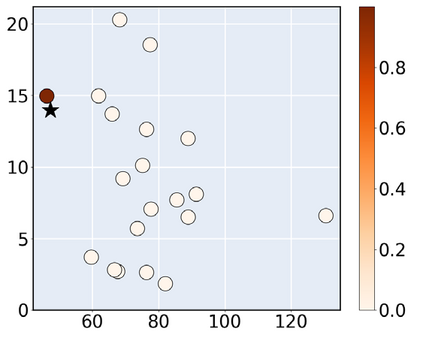
Consider a scenario where we are supplied with a number of ready-to-use models trained on a certain source domain and hope to directly apply the most appropriate ones to different target domains based on the models' relative performance. Ideally we should annotate a validation set for model performance assessment on each new target environment, but such annotations are often very expensive. Under this circumstance, we introduce the problem of ranking models in unlabeled new environments. For this problem, we propose to adopt a proxy dataset that 1) is fully labeled and 2) well reflects the true model rankings in a given target environment, and use the performance rankings on the proxy sets as surrogates. We first select labeled datasets as the proxy. Specifically, datasets that are more similar to the unlabeled target domain are found to better preserve the relative performance rankings. Motivated by this, we further propose to search the proxy set by sampling images from various datasets that have similar distributions as the target. We analyze the problem and its solutions on the person re-identification (re-ID) task, for which sufficient datasets are publicly available, and show that a carefully constructed proxy set effectively captures relative performance ranking in new environments. Code is available at \url{https://github.com/sxzrt/Proxy-Set}.
翻译:考虑一个假设方案,即我们获得在某个源域上培训的一些现成使用模型,并希望根据模型相对性能,将最适当的模型直接应用于不同的目标领域。理想的是,我们应该为每个新目标环境的模型性能评估提供一套鉴定,但这种说明往往非常昂贵。在这种情况下,我们提出在未贴标签的新环境中的排名模型问题。对于这个问题,我们提议采用一个代理数据集,即(1) 完全贴上标签,(2) 充分反映特定目标环境中的真正模型等级,并使用代用数据集的性能排名作为代用数据。我们首先选择标签数据集作为代用数据。具体地说,找到与未贴标签的目标领域更相似的数据集,以更好地保存相对性能排名。我们为此,我们进一步提议从分布相近的各种数据集中抽样搜索代用图集。我们分析了问题及其在某个目标环境中重新识别(重新识别)任务(重新识别)时的解决方案,并公开提供足够数据集,并显示一个仔细构建的代理性能排序。SProgirx /comrrr/ 有效测量了一个新的环境。