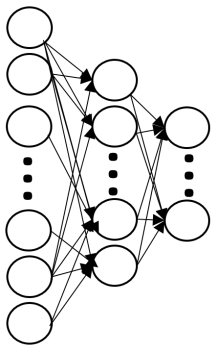
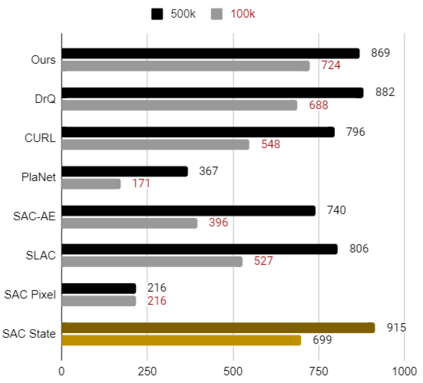
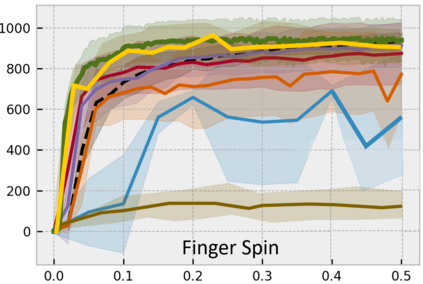
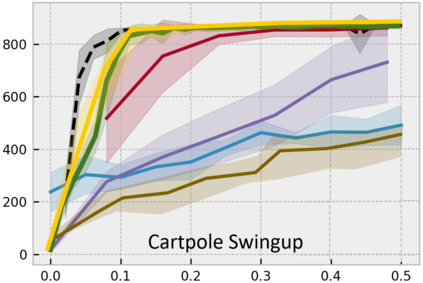
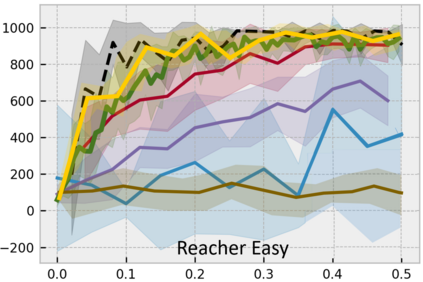
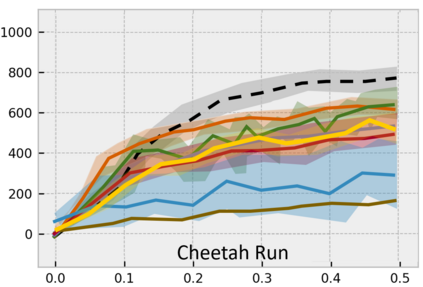
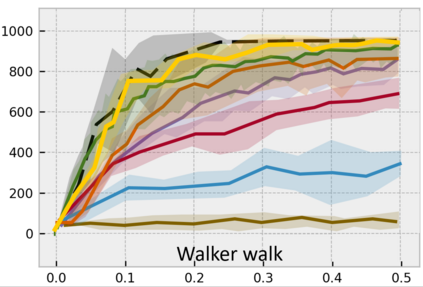
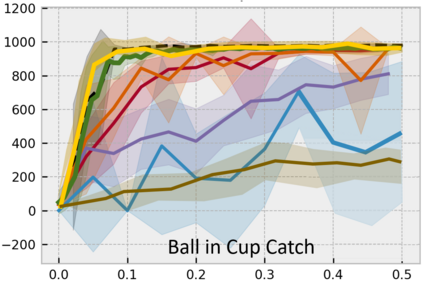
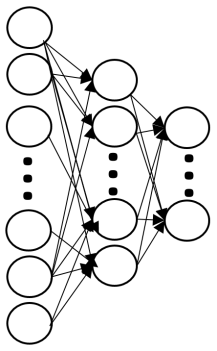
Developing an agent in reinforcement learning (RL) that is capable of performing complex control tasks directly from high-dimensional observation such as raw pixels is yet a challenge as efforts are made towards improving sample efficiency and generalization. This paper considers a learning framework for Curiosity Contrastive Forward Dynamics Model (CCFDM) in achieving a more sample-efficient RL based directly on raw pixels. CCFDM incorporates a forward dynamics model (FDM) and performs contrastive learning to train its deep convolutional neural network-based image encoder (IE) to extract conducive spatial and temporal information for achieving a more sample efficiency for RL. In addition, during training, CCFDM provides intrinsic rewards, produced based on FDM prediction error, encourages the curiosity of the RL agent to improve exploration. The diverge and less-repetitive observations provide by both our exploration strategy and data augmentation available in contrastive learning improve not only the sample efficiency but also the generalization. Performance of existing model-free RL methods such as Soft Actor-Critic built on top of CCFDM outperforms prior state-of-the-art pixel-based RL methods on the DeepMind Control Suite benchmark.
翻译:由于努力提高样本效率和一般化,因此开发能够直接从高维观测(如生像素等)中执行复杂控制任务的强化学习剂(RL)还是一项挑战,因为正在努力提高样本效率和一般化。本文件认为,在直接以生像素为基础实现更具样本效率的强化学习剂(RL)方面,CFDMD采用一个前瞻性动态模型(FDM),并进行对比学习,以训练其深层的进化神经网络图像编码(IE),以获取有利的空间和时间信息,提高RL的样本效率。此外,在培训期间,CCDDM提供基于FDM预测错误产生的内在奖赏,鼓励RL代理的好奇心来改进勘探。我们的探索战略和对比性学习中的数据增强所提供的差异性和较少的观测不仅提高了样本效率,而且提高了一般化。在CFDDDDDM前的顶端上建的Soft Acor-Critict 等现有无型RL方法的绩效,例如,在CFDDM-Rix-FM-S-CRADR-R-C-R-CFRADM-RADM-RDM-S-RDM-RDM-L上以前的基的基的基的基方法上。