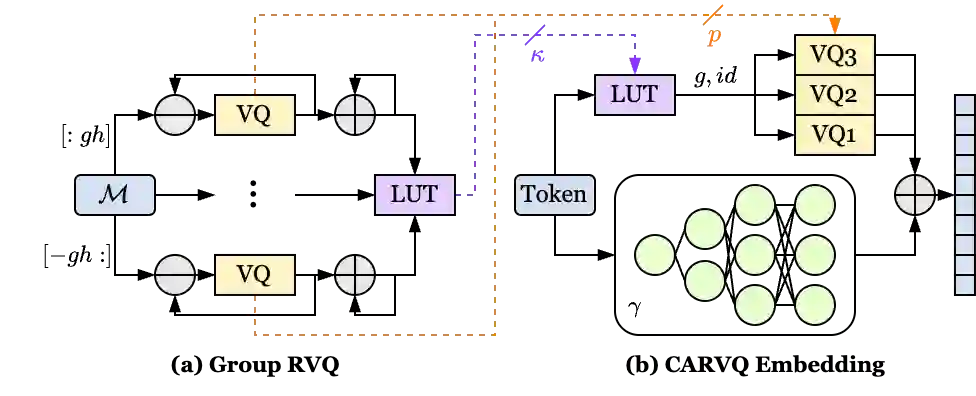
Large Language Models (LLMs) typically rely on a large number of parameters for token embedding, leading to substantial storage requirements and memory footprints. In particular, LLMs deployed on edge devices are memory-bound, and reducing the memory footprint by compressing the embedding layer not only frees up the memory bandwidth but also speeds up inference. To address this, we introduce CARVQ, a post-training novel Corrective Adaptor combined with group Residual Vector Quantization. CARVQ relies on the composition of both linear and non-linear maps and mimics the original model embedding to compress to approximately 1.6 bits without requiring specialized hardware to support lower-bit storage. We test our method on pre-trained LLMs such as LLaMA-3.2-1B, LLaMA-3.2-3B, LLaMA-3.2-3B-Instruct, LLaMA-3.1-8B, Qwen2.5-7B, Qwen2.5-Math-7B and Phi-4, evaluating on common generative, discriminative, math and reasoning tasks. We show that in most cases, CARVQ can achieve lower average bitwidth-per-parameter while maintaining reasonable perplexity and accuracy compared to scalar quantization. Our contributions include a novel compression technique that is compatible with state-of-the-art transformer quantization methods and can be seamlessly integrated into any hardware supporting 4-bit memory to reduce the model's memory footprint in memory-constrained devices. This work demonstrates a crucial step toward the efficient deployment of LLMs on edge devices.
翻译:大语言模型通常依赖大量参数进行词元嵌入,导致巨大的存储需求和内存占用。特别是在边缘设备上部署的LLMs受限于内存,通过压缩嵌入层来减少内存占用不仅能释放内存带宽,还能加速推理。为此,我们提出CARVQ,一种结合分组残差向量量化的后训练新型校正适配器。CARVQ依赖于线性和非线性映射的组合,通过模拟原始模型嵌入实现约1.6比特的压缩,且无需专用硬件支持低位存储。我们在LLaMA-3.2-1B、LLaMA-3.2-3B、LLaMA-3.2-3B-Instruct、LLaMA-3.1-8B、Qwen2.5-7B、Qwen2.5-Math-7B和Phi-4等预训练大语言模型上测试了该方法,并在常见生成式、判别式、数学和推理任务上进行了评估。结果表明,在多数情况下,与标量量化相比,CARVQ能以更低的平均每参数比特数保持合理的困惑度和准确率。我们的贡献包括一种与先进Transformer量化方法兼容的新型压缩技术,可无缝集成到任何支持4位内存的硬件中,从而降低内存受限设备的模型内存占用。这项工作为实现大语言模型在边缘设备上的高效部署迈出了关键一步。