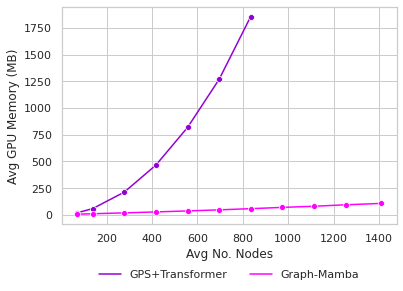
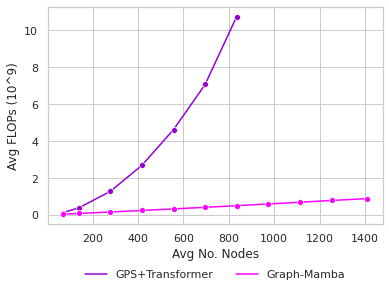
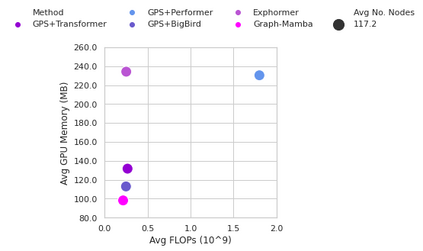
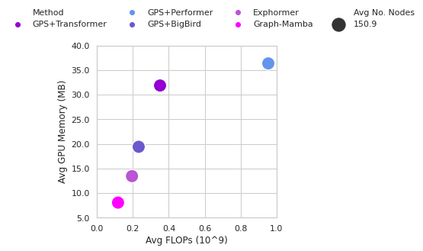
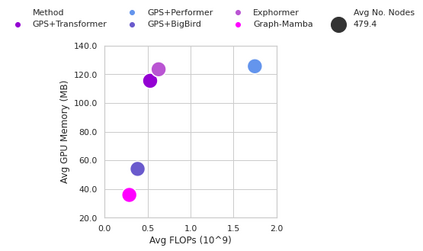
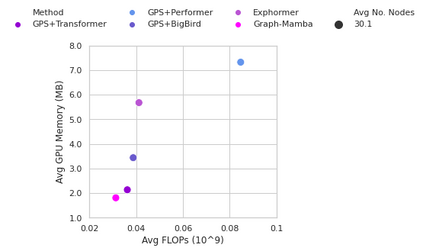
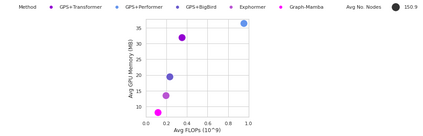
Attention mechanisms have been widely used to capture long-range dependencies among nodes in Graph Transformers. Bottlenecked by the quadratic computational cost, attention mechanisms fail to scale in large graphs. Recent improvements in computational efficiency are mainly achieved by attention sparsification with random or heuristic-based graph subsampling, which falls short in data-dependent context reasoning. State space models (SSMs), such as Mamba, have gained prominence for their effectiveness and efficiency in modeling long-range dependencies in sequential data. However, adapting SSMs to non-sequential graph data presents a notable challenge. In this work, we introduce Graph-Mamba, the first attempt to enhance long-range context modeling in graph networks by integrating a Mamba block with the input-dependent node selection mechanism. Specifically, we formulate graph-centric node prioritization and permutation strategies to enhance context-aware reasoning, leading to a substantial improvement in predictive performance. Extensive experiments on ten benchmark datasets demonstrate that Graph-Mamba outperforms state-of-the-art methods in long-range graph prediction tasks, with a fraction of the computational cost in both FLOPs and GPU memory consumption. The code and models are publicly available at https://github.com/bowang-lab/Graph-Mamba.
翻译:暂无翻译