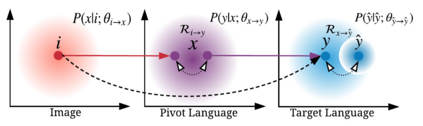
Image captioning is a multimodal task involving computer vision and natural language processing, where the goal is to learn a mapping from the image to its natural language description. In general, the mapping function is learned from a training set of image-caption pairs. However, for some language, large scale image-caption paired corpus might not be available. We present an approach to this unpaired image captioning problem by language pivoting. Our method can effectively capture the characteristics of an image captioner from the pivot language (Chinese) and align it to the target language (English) using another pivot-target (Chinese-English) sentence parallel corpus. We evaluate our method on two image-to-English benchmark datasets: MSCOCO and Flickr30K. Quantitative comparisons against several baseline approaches demonstrate the effectiveness of our method.
翻译:图像字幕是一项多式任务,涉及计算机视觉和自然语言处理,目标是从图像到自然语言描述学习绘图,一般而言,制图功能是从一组图像字幕培训中学习的,但对某些语言来说,可能没有大规模图像字幕配对功能。我们提出一种方法,通过语言支线解决这一未配对图像字幕问题。我们的方法可以有效地捕捉主轴语言(中文)的图像字幕特征,并使用另一个主轴-目标(中文-英文)平行句子(英文)将其与目标语言(英文)相匹配。我们评估了我们关于两个图像-英文基准数据集的方法:MCCO和Flick30K。 与若干基线方法的定量比较显示了我们方法的有效性。