业界 | 腾讯 AI Lab 斩获 MSCOCO Captions 冠军,领衔图像描述生成技术
AI 科技评论按:图像描述生成技术是一个计算机视觉与 NLP 交叉研究领域的研究领域,在如今的浪潮下更显火热。今年8月,腾讯 AI Lab 凭借自主研发的强化学习算法在微软 MS COCO 相关的 Image Captioning 任务上排名第一,超过了微软、谷歌、IBM 等参赛公司。
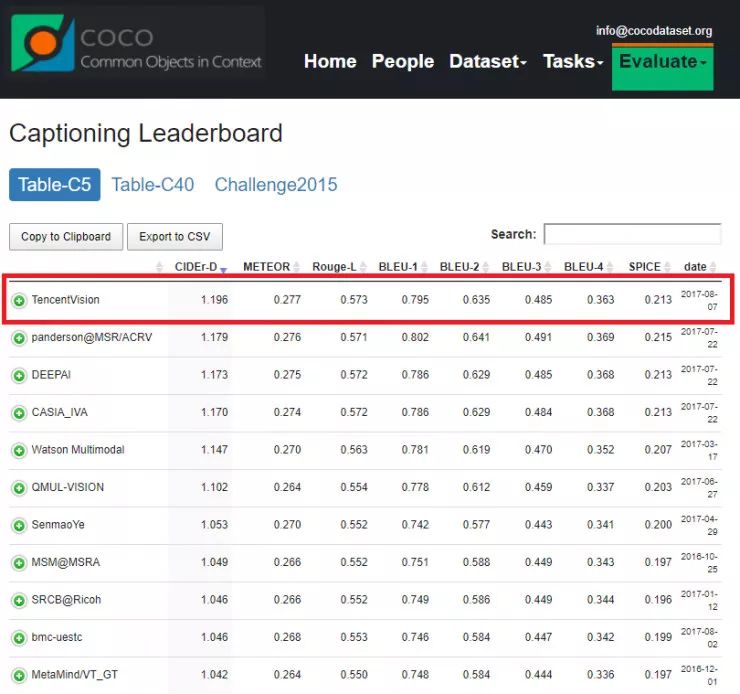
MS COCO (Microsoft Common Objects in Context,常见物体图像识别) 数据集(http://cocodataset.org/)是由微软发布并维护的图像数据集。在这个数据集上,共有物体检测 (Detection)、人体关键点检测 (Keypoints)、图像分割 (Stuff)、图像描述生成 (Captions) 四个类别的比赛任务。由于这些视觉任务是计算机视觉领域当前最受关注和最有代表性的,MS COCO 成为了图像理解与分析方向最重要的标杆之一。其中图像描述生成任务 (Captions),需要同时对图像与文本进行深度的理解与分析,相比其他三个任务更具有挑战性,因此也吸引了更多的工业界(Google,IBM,Microsoft)以及国际顶尖院校(UC Berkeley、Stanford University)的参赛队伍,迄今共有 80 个队伍参与这项比赛。
通俗来说,图像描述生成(image captioning)研究的是使机器拥有人类理解图像的能力,并用人类语言描述感知到的图像内容。图像描述生成使得机器可以帮助有视觉障碍的人来理解图像,给图像提供除了标签(tag)以外更加丰富的描述,因此这项任务具有广泛的实际意义。
从学术研究的角度来说,图像描述生成的研究不仅仅需要理解图像,更需要理解自然语言,是一个跨学科跨模态的交叉研究课题,也是对深度神经网络的学习能力向多个数据域扩展的一步重要的探索。因此,众多科技企业和科研机构参与了此任务,包括 Google [1][3]、Microsoft [5]、IBM [2]、Snapchat [4]、Montreal/Toronto University [6]、UC Berkeley [7]、 Stanford University [8]、百度 [9] 等。
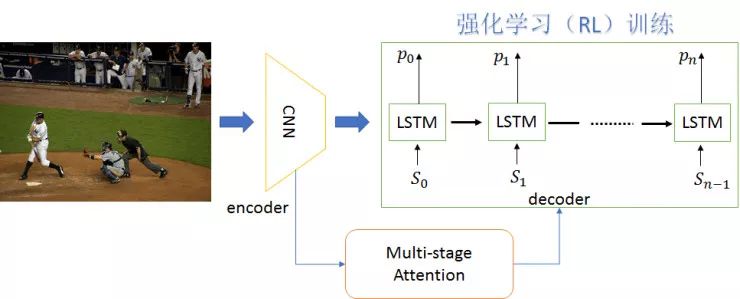
最近,腾讯 AI Lab 研发了新的强化学习算法(Reinforcement Learning)以进一步提高图像描述生成的模型能力,如上图所示。相应的图像描述生成模型,采用了编码器-解码器(encoder-decoder)[1] 的框架,同时引入了注意力(attention)的机制 [3]。基于之前研究的空间和通道注意力模型(spatial and channel-wise attention)[10] 的研究成果, AI Lab 构建了新网络模型引入了一个多阶段的注意力机制(Multi-stage Attention)。编码器,使用已有的图像卷积神经网络(CNN)如 VGG,Inception,ResNet 等,将给定的图像编码成为蕴含图像语义信息的向量。
这些向量能够表征图像不同尺度的语义信息,譬如全局的语义、多尺度的局部语义。解码器,使用当前最流行的长短时记忆模型(LSTM),将编码器得到的图像的全局和局部语义向量,解码生成描述图像内容的文本语句。正是在解码的过程中,AI Lab 创新性地使用了多阶段的注意力机制:将图像不同尺度的局部语义信息,通过不同阶段的注意力模块,嵌入到每一个单词的生成过程中;同时注意力模块需要考虑不同尺度引入的不同阶段的注意力信号强弱。
除了引入多阶段的注意力机制,AI Lab 所研发的强化学习算法能进一步提升构建的网络模型的训练效果。使用传统的交叉熵(cross entropy)作为损失函数进行训练,无法充分地优化图像描述生成的衡量指标,譬如 BLEU,METEOR,ROUGE,CIDER,SPICE 等。这些衡量指标作为损失函数都是不可微的。针对此不可微的问题,AI Lab 使用强化学习算法训练网络模型以优化这些衡量指标。
训练过程可以总结为以下几个阶段:
给定一幅图像,通过深度网络模型产生相应的语句;
将相应的语句与标注语句比对以计算相应的衡量指标;
使用强化学习构建深度网络模型的梯度信息,执行梯度下降完成网络的最终优化。
经过充分的训练,腾讯 AI Lab 研发的图像描述生成模型在微软 MS COCO 的 Captions 任务上排名第一,超过了微软、谷歌、IBM 等科技公司。
[1]. O. Vinyals, A. Toshev, S. Bengio, and D. Erhan,「Show and Tell: A Neural Image Caption Generator」, CVPR 2015.
[2]. S. J. Rennie, E. Marcheret, Y. Mroueh, J. Ross, and V. Goel,「Self-critical Sequence Training for Image Captioning」, CVPR 2017.
[3]. S. Liu; Z. Zhu; N. Ye; S. Guadarrama; and K. Murphy,「Improved Image Captioning via Policy Gradient Optimization of SPIDEr」, ICCV 2017.
[4]. Z. Ren, X. Wang, N. Zhang, X. Lv, and Li-Jia Li,「Deep Reinforcement Learning-Based Image Captioning With Embedding Reward」, CVPR 2017.
[5]. H. Fang, S. Gupta, F. Iandola, R. Srivastava, L. Deng, P. Dollár, J. Gao, X. He, M. Mitchell, J. Platt, C.L. Zitnick, and G. Zweig,「From Captions to Visual Concepts and Back」, CVPR 2015.
[6]. K. Xu, J. Ba, R. Kiros, K. Cho, A. Courville, R. Salakhudinov, R. Zemel, and Y. Bengio. Show,「Attend and Tell: Neural Image Caption Generation with Visual Attention」, ICML 2015.
[7]. J. Donahue, L. Hendricks, S. Guadarrama, M. Rohrbach, S. Venugopalan, K. Saenko, and T. Darrell,「Long-term Recurrent Convolutional Networks for Visual Recognition and Description」, CVPR 2015.
[8]. A. Karpathy and Li Fei-Fei,「Deep Visual-Semantic Alignments for Generating Image Descriptions」, CVPR 2015.
[9]. J. Mao, W. Xu, Y. Yang, J. Wang, and A. L. Yuille,「Deep Captioning with Multimodal Recurrent Neural Networks (m-RNN)」, ICLR 2015.
[10]. L. Chen, H. Zhang, J. Xiao, L. Nie, J. Shao, W. Liu, and T. Chua,「SCA-CNN: Spatial and Channel-wise Attention in Convolutional Networks for Image Captioning」, CVPR 2017.
————— 给爱学习的你的福利 —————
随着大众互联网理财观念的逐步普及,理财规模随之扩大,应运而生的智能投顾,成本低、风险分散、无情绪化,越来越多的中产阶层、大众富裕阶层已然在慢慢接受。王蓁博士将以真实项目带你走上智能投顾之路,详情请识别下图二维码或点击文末阅读原文~






