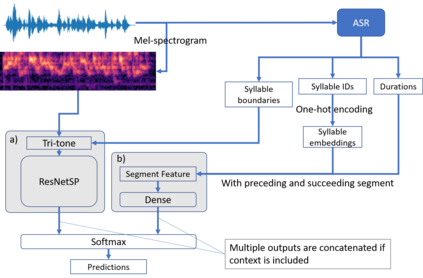
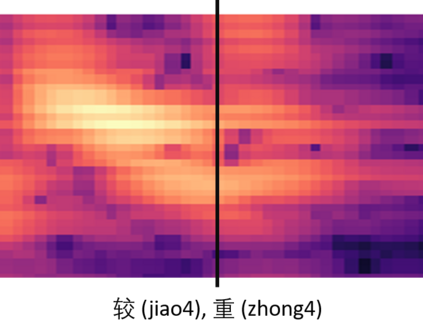
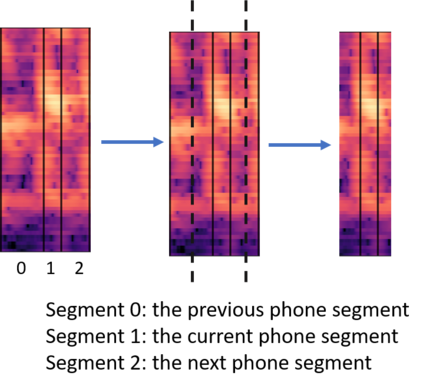
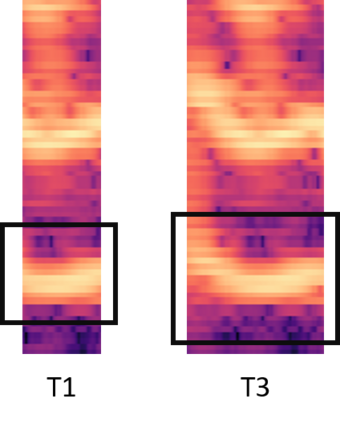
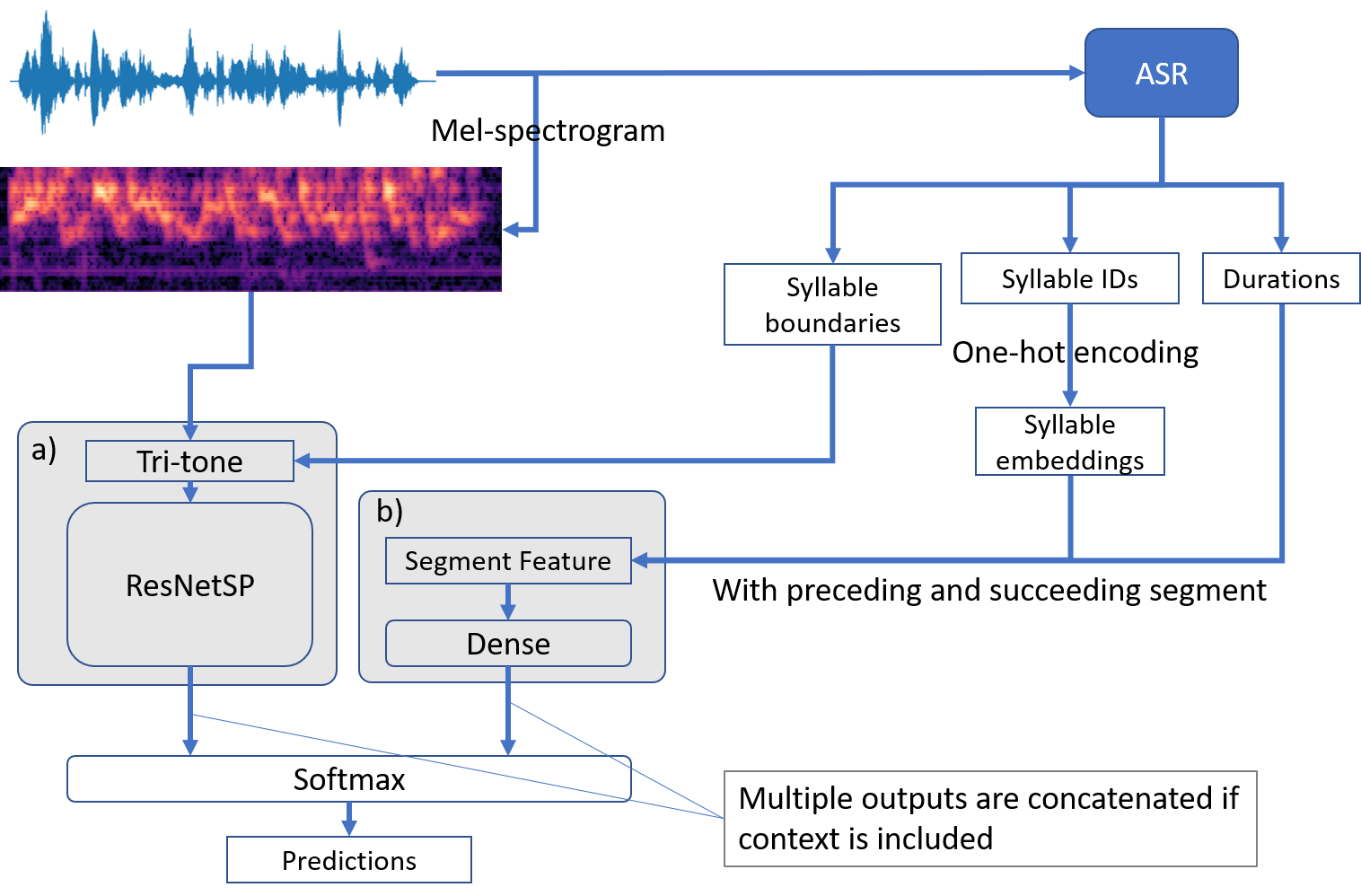
In this paper, we propose an end-to-end Mandarin tone classification method from continuous speech utterances utilizing both the spectrogram and the short term context information as the inputs. Both Mel-spectrograms and context segment features are used to train the tone classifier. We first divide the spectrogram frames into syllable segments using force alignment results produced by an ASR model. Then we extract the short term segment features to capture the context information across multiple syllables. Feeding both the Mel-spectrogram and the short term context segment features into an end-to-end model could significantly improve the performance. Experiments are performed on a large scale open source Mandarin speech dataset to evaluate the proposed method. Results show that the this method improves the classification accuracy from $79.5\%$ to $88.7\%$ on the AISHELL3 database.
翻译:在本文中,我们提议使用光谱和短期背景信息作为投入,从连续语音语句中采用端到端的普通话语调分类方法。使用梅尔光谱和上下文部分功能来训练音调分类员。我们首先使用ASR模型产生的对齐结果将光谱框架分成可音频部分。然后,我们提取短期部分功能,以捕捉跨多个音频的上下文信息。将Mel光谱和短期上下文部分功能输入一个端到端模式可以大大改善性能。实验是在大规模开放源曼达林语语音数据集上进行的,以评价拟议方法。结果显示,这种方法将分类的准确性从79.5美元提高到AISHELL3数据库的88.7美元。