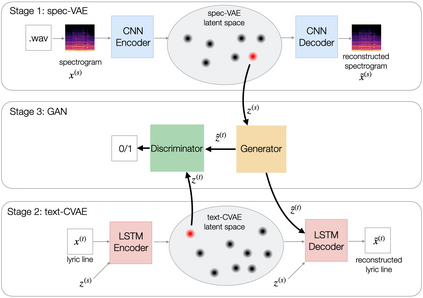
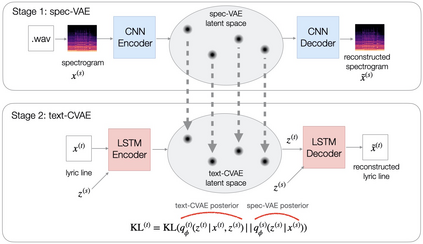
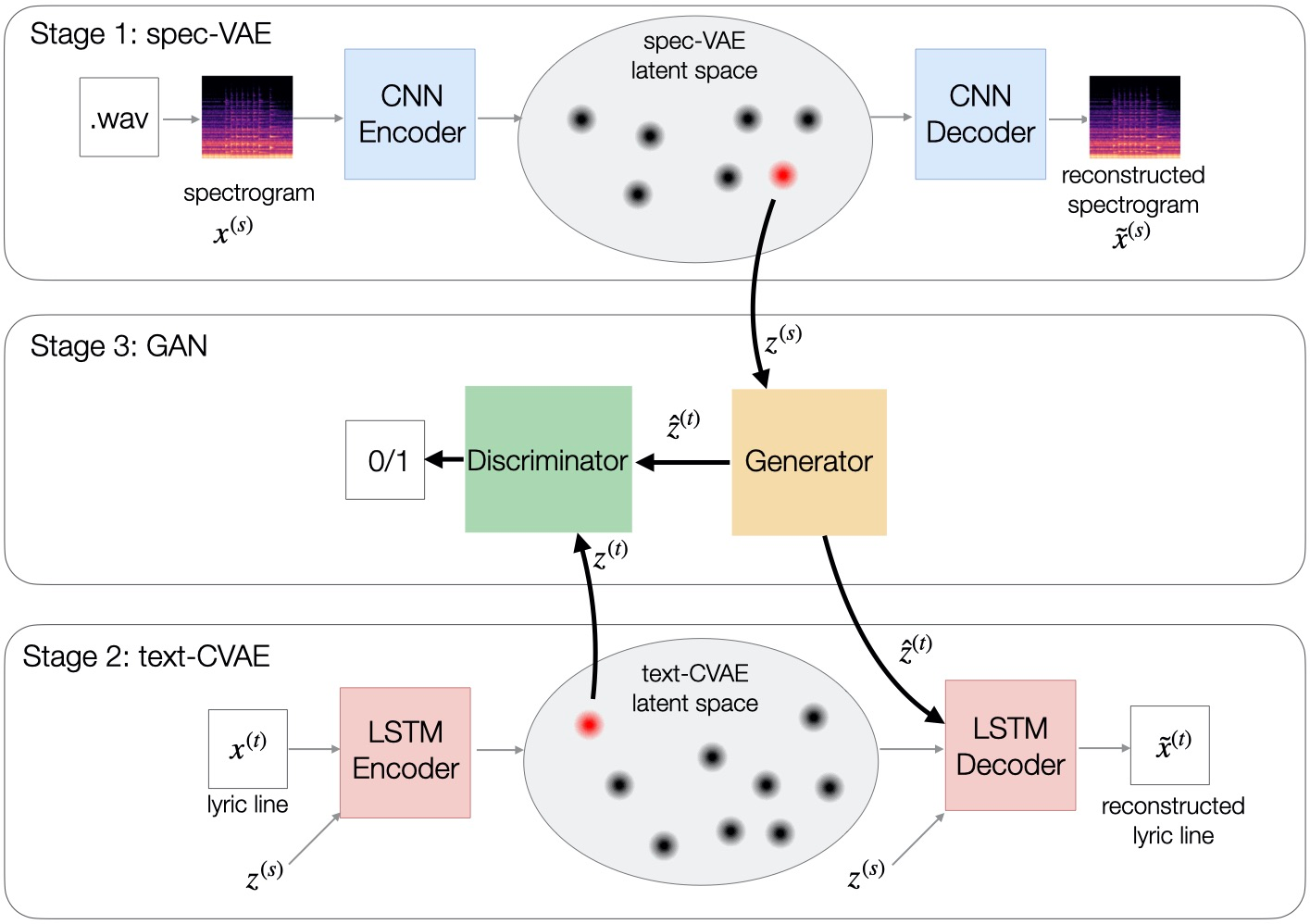
We describe a real-time system that receives a live audio stream from a jam session and generates lyric lines that are congruent with the live music being played. Two novel approaches are proposed to align the learned latent spaces of audio and text representations that allow the system to generate novel lyric lines matching live instrumental music. One approach is based on adversarial alignment of latent representations of audio and lyrics, while the other approach learns to transfer the topology from the music latent space to the lyric latent space. A user study with music artists using the system showed that the system was useful not only in lyric composition, but also encouraged the artists to improvise and find new musical expressions. Another user study demonstrated that users preferred the lines generated using the proposed methods to the lines generated by a baseline model.
翻译:我们描述一个实时系统,这个系统接收来自干扰会话的现场音频流,并生成与正在播放的现场音乐一致的音频线条。我们提出两种新颖的办法,使所学的音频和文字表达空间的潜在空间能够使系统产生与现场工具音乐相匹配的新型歌词线。一种办法是对音频和歌词的潜在表达形式进行对立,而另一种办法是将表层学从音乐潜藏空间转移到高音潜藏空间。与使用该系统的音乐艺术家进行的用户研究表明,该系统不仅在歌词组成方面有用,而且还鼓励艺术家即兴创作和寻找新的音乐表达形式。另一个用户研究表明,用户倾向于使用拟议方法生成的文字线条与基线模型生成的线条进行对立。