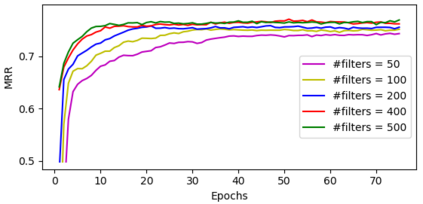
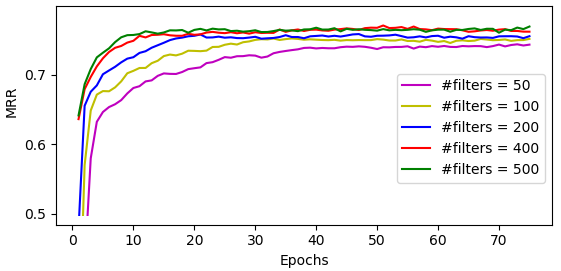
In this paper, we introduce an embedding model, named CapsE, exploring a capsule network to model relationship triples (subject, relation, object). Our CapsE represents each triple as a 3-column matrix where each column vector represents the embedding of an element in the triple. This 3-column matrix is then fed to a convolution layer where multiple filters are operated to generate different feature maps. These feature maps are reconstructed into corresponding capsules which are then routed to another capsule to produce a continuous vector. The length of this vector is used to measure the plausibility score of the triple. Our proposed CapsE obtains better performance than previous state-of-the-art embedding models for knowledge graph completion on two benchmark datasets WN18RR and FB15k-237, and outperforms strong search personalization baselines on SEARCH17.
翻译:在本文中,我们引入了一个嵌入模型,名为 CapsE, 探索一个模范关系三重( 主题、 关系、 对象) 的胶囊网络。 我们的胶囊E 代表每个三重矩阵, 每个柱矢量代表三重元素的嵌入。 这个三列矩阵随后被装入一个卷变层, 在那里运行多个过滤器以生成不同的特征地图。 这些特征地图被重建成相应的胶囊, 然后被连接到另一个胶囊中以生成一个连续矢量。 这个矢量的长度被用来测量三重体的概率。 我们提议的卡布E 取得了比之前最先进的嵌入模型更好的性能, 用于在两个基准数据集 WN18RRR 和 FB15k-237 上完成知识图, 并且超越了 SEARCH17 上的强搜索个人化基线 。