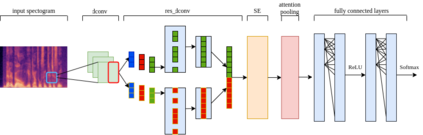
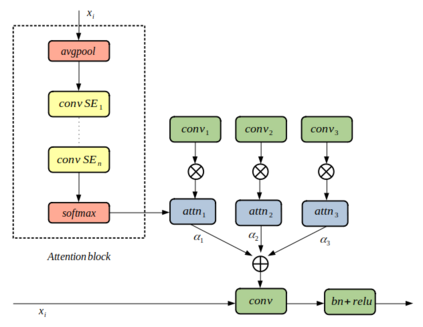
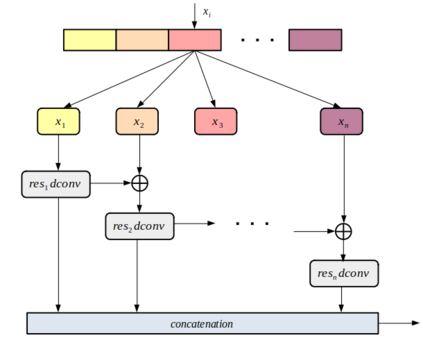
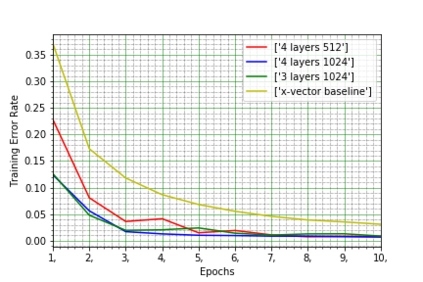
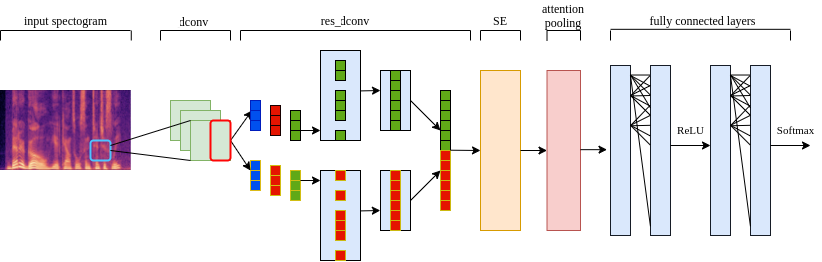
State-of-the-art speaker verification frameworks have typically focused on speech enhancement techniques with increasingly deeper (more layers) and wider (number of channels) models to improve their verification performance. Instead, this paper proposes an approach to increase the model resolution capability using attention-based dynamic kernels in a convolutional neural network to adapt the model parameters to be feature-conditioned. The attention weights on the kernels are further distilled by channel attention and multi-layer feature aggregation to learn global features from speech. This approach provides an efficient solution to improving representation capacity with lower data resources. This is due to the self-adaptation to inputs of the structures of the model parameters. The proposed dynamic convolutional model achieved 1.62\% EER and 0.18 miniDCF on the VoxCeleb1 test set and has a 17\% relative improvement compared to the ECAPA-TDNN.
翻译:最先进的演讲者核查框架通常侧重于语言增强技术,其改进核查绩效的模式越发深入(层层越多),范围越广(频道数量越多),提高语言增强技术,相反,本文件建议采用一种方法,利用在进化神经网络中基于关注的动态内核,提高示范分辨率能力,以调整模型参数参数参数,使模型参数具有特定条件;通过频道关注和多层特征汇总,进一步吸引了对内核的注意,以便从演讲中学习全球特征;这一方法为利用较少的数据资源提高代表能力提供了有效的解决办法;这是因为对模型参数结构的投入进行了自我调整;拟议的动态共生模型在VoxCeleb1测试集上实现了1.62°EER和0.18°MDCF,与ECAPA-TDNNN相比有了17个相对改进。