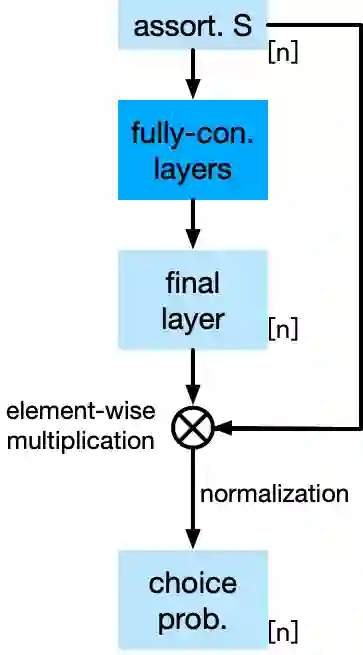
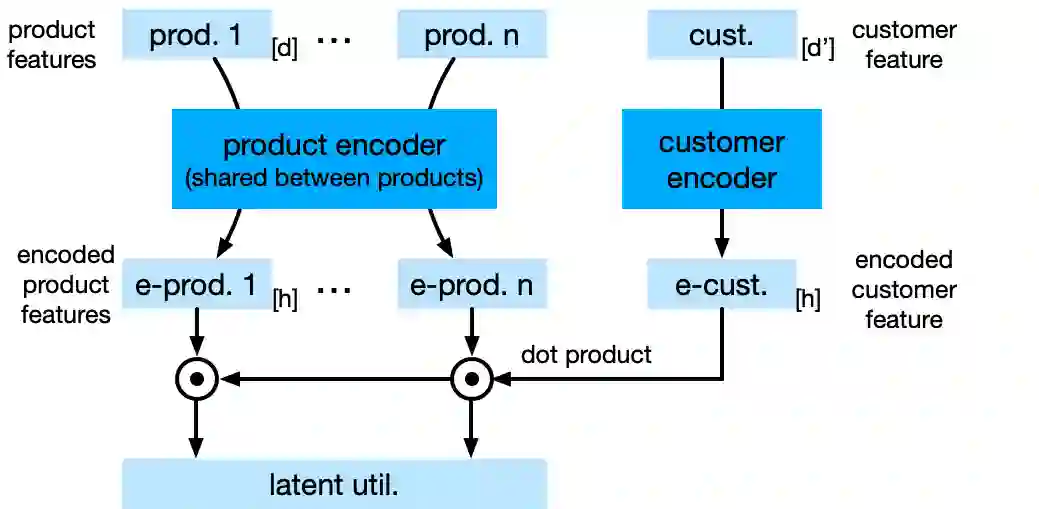
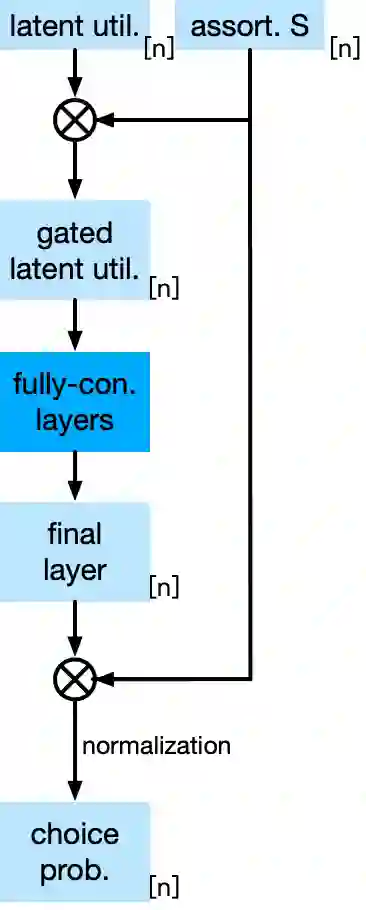
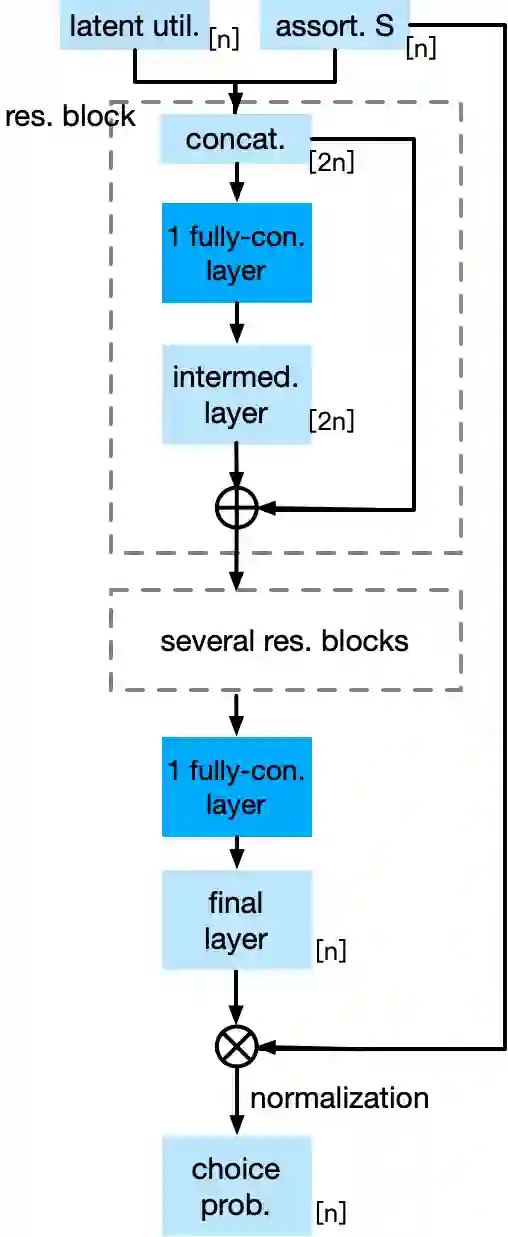
Choice modeling has been a central topic in the study of individual preference or utility across many fields including economics, marketing, operations research, and psychology. While the vast majority of the literature on choice models has been devoted to the analytical properties that lead to managerial and policy-making insights, the existing methods to learn a choice model from empirical data are often either computationally intractable or sample inefficient. In this paper, we develop deep learning-based choice models under two settings of choice modeling: (i) feature-free and (ii) feature-based. Our model captures both the intrinsic utility for each candidate choice and the effect that the assortment has on the choice probability. Synthetic and real data experiments demonstrate the performances of proposed models in terms of the recovery of the existing choice models, sample complexity, assortment effect, architecture design, and model interpretation.
翻译:选择模型是研究经济、营销、业务研究和心理学等许多领域的个人偏好或实用性研究的一个中心议题,虽然绝大多数关于选择模型的文献都专门讨论了导致管理和决策见解的分析属性,但从经验数据中学习选择模型的现有方法往往不是在计算上难以,就是抽样效率低下。在本文中,我们在两种选择模型环境下开发了深层次的基于学习的选择模型:(一) 无特征和(二) 基于特征的模型。我们的模型既捕捉了每个候选人选择的内在效用,又捕捉了分类对选择概率的影响。合成和真实数据实验展示了拟议模型在恢复现有选择模型、样本复杂性、分类效应、结构设计和模型解释方面的表现。